
1. PPO算法介绍
PPO算法通过使用剪辑的目标函数和多次小步更新,保证了策略更新的稳定性和样本效率。它适合处理高维连续动作空间的问题,并且在实践中表现出较好的稳定性和收敛速度。
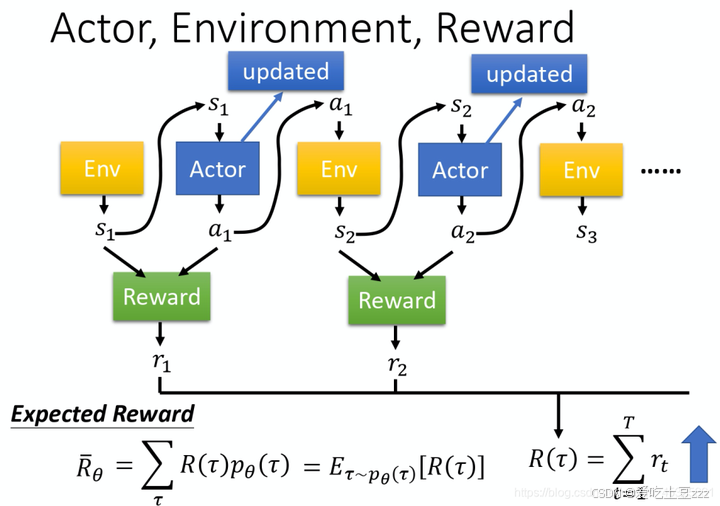 编辑
编辑
1)策略更新的目标函数
- PPO的核心是通过优化一个剪辑的目标函数来更新策略。
- 目标函数: LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
- rt(θ)=πθ(at|st)πθold(at|st) 是当前策略和旧策略的概率比
- A^t 是优势函数的估计值
- ϵ 是一个小的超参数,控制策略更新的范围
- 通过最小化被剪辑后的目标函数,PPO限制了策略更新的幅度,避免过大的更新导致不稳定。
2) 优势函数估计
- PPO算法使用优势函数 A^t 来度量在状态 st 下采取动作 at 的好坏。常用的优势函数估计方法有GAE(Generalized Advantage Estimation)。
- 计算公式: A^t=∑l=0∞(γλ)lδtV
其中 δtV=rt+γV(st+1)−V(st) , γ 是折扣因子, λ 是GAE的衰减系数。
3)多次小步更新
- PPO不像传统的策略梯度方法进行大步更新,而是通过多次小步更新来提高策略。这样可以在保持策略更新稳定的同时提高样本效率。
- 每次更新时,PPO从旧策略 θold 开始,以一定次数的迭代更新策略参数 θ ,确保在小范围内改进策略。
4)价值网络更新
- PPO通常使用一个价值函数 ( V(s_t; \phi) ) 来估计每个状态的价值,这个函数是通过最小化均方误差(MSE)来训练的: LVF(ϕ)=12Et[(V(st;ϕ)−Vttarget)2]
- 通过同时更新策略网络和价值网络,PPO可以更好地利用当前策略下的估计值,提高训练效率。
5)随机小批量优化
PPO在更新过程中通常采用随机小批量(mini-batch)梯度下降的方法。通过对每个小批量的数据进行优化,可以更有效地利用经验,提高训练速度。
6)经验回放
PPO在训练过程中使用每个时间步的数据进行优化,但不会像DQN那样使用经验回放。它在每个时间步收集数据并使用这些数据直接优化目标函数,以保证策略更新的一致性。
2. 环境
- python3.8.5
- 若干库
3. 代码
1)主函数
主函数中负责执行追捕者和逃逸者的训练函数,并用于测试。
1 | import matplotlib.pyplot as plt |
其中,追捕者的训练函数如下:
1 | def train_network(args, env, show_picture=True, pre_train=False, d_capture=0): |
首先,初始化环境参数,包括网络输出尺度action_dim,输出最大值max_action,智能体状态尺度state_dim,抓捕距离d_capture。
定义经验池replay_buffer,用于存储智能体在环境中的训练数据,比如奖励,状态等。智能体需要通过经验池提取数据进行训练。
定义智能体pursuer_agent、evader_agent,其实也就是ppo网络的实例,用于选择动作action
开始训练:
- 环境初始化**env.reset(0)**,0表示追捕者训练,1表示逃逸者训练,2表示测试,获取初始状态s
- 智能体选择动作:pursuer_agent.choose_action(s),从环境中获取到状态后,根据当前状态获取下一步的执行动作action
- 将智能体的动作输入值环境中,执行step函数,动作的奖励值r、状态s_、以及完成标志done
- 将s, puruser_action, puruser_a_logprob, r, s_, dw, done存储至经验池,保留数据以待训练
- s = s_,重新赋值状态,用于智能体选择动作
- 循环执行第二步~第五步
- 如果经验池储蓄满,更新追捕者网络参数:pursuer_agent.update(replay_buffer, epsiode)
最后,训练完成后保存训练模型
1 | pursuer_agent.save_checkpoint() |
同理,逃逸星和测试函数的步骤类似,只不过测试函数不需要更新网络
2)environment
该文件主要负责与智能体进行交互,获取奖励值以及动作的状态值
1 | import numpy as np |
satellites
:环境定义类
- Pursuer_position,Pursuer_vector,Escaper_position,Escaper_vector:智能体位置速度,用xyz坐标表示
- d_capture:抓捕距离,当追捕者和逃逸者的相对距离逼近该距离时,判定追捕者成功
- fuel_c,fuel_t:追逃双方的燃料
- win_reward:成功奖励值,追捕者抓捕成功后,获得该奖励值
- observation_space:观测空间状态,一共18位,包括追逃双方状态差值、追逃双方的状态
- action_space:智能体动作脉冲,上下限分别位-1.6、1.6,一共三位,包含在xyz轴
- 其他参数:其他self参数可以忽略,在简单的追逃任务中使用不到
1 | def reset(self, Flag): |
初始化函数,智能体获得初始状态(位置、速度以及初始奖励值),并将状态返回
1 | def step(self, pursuer_action, escaper_action, epsiode_count): |
step函数,负责智能体与环境的交互。
首先,将智能体的动作进行限制,动作上下限位[-1.6,1.6],并计算剩余燃料(简单的减去脉冲绝对值)。
更改航天器速度,智能体的动作为脉冲,脉冲施加在航天器更改其状态。
航天器轨道外推模型:
- 拉格朗日外推模型
- CW状态转移矩阵
- 数值外推
代码分别如下:
*拉格朗日外推模型*
1 | // 拉格朗日外推模型 |
*CW状态矩阵*
1 | def State_transition_matrix(self, t): |
*数值外推法*
1 | class Numerical_calculation_method(): |
通过这三种外推模型进行下一状态的求解,并根据航天器新的状态求解奖励值:
具体分为三类:
1 | self.pursuer_reward = 1 if self.dis < dis else -1 # 接近目标给予奖励 |
如果追捕者逼近,那么奖励1
1 | self.pursuer_reward += -1 if self.d_capture <= self.dis <= 4 * self.d_capture else -2 # 在目标距离范围内给予奖励 |
如果追捕者保持在一定范围内,鼓励1
1 | pv1 = self.reward_of_action3(self.Pursuer_position) |
其他奖励函数,这些可以自己设定
最后返回航天器最新状态,追捕者奖励值和任务成功标志位
3)replaybuffer
经验池代码
1 | import numpy as np |
4)ppo
PPO网络文件,包括ac框架以及网络更新机制
1 | # --coding:utf-8-- |
5)训练
1 | if __name__ == "__main__": |
- chkpt_dir:模型文件地址,如果进行测试test,那么需要把该地址设置为你的模型文件地址
- env :可手动修改航天器初始状态
- train:训练标志,true为训练,false为测试
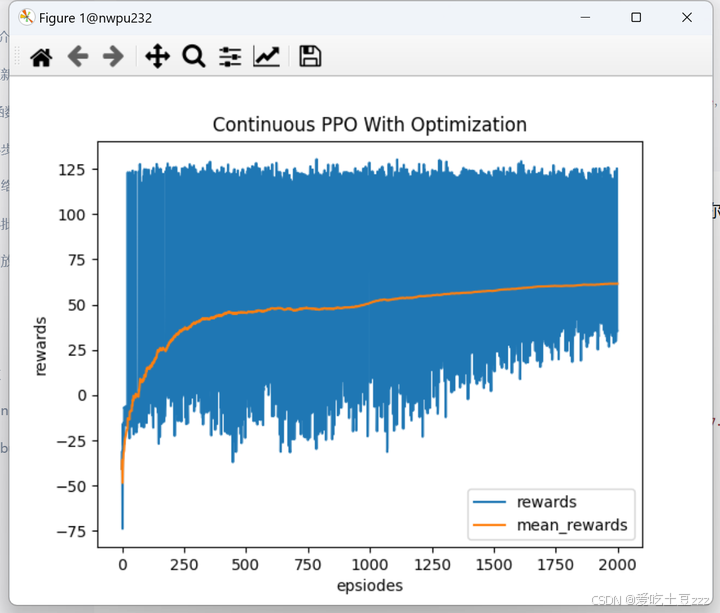
训练过程:

训练结果:
测试:

分数很高,以及成功抓捕
参考:
基于强化学习的空战辅助决策(2D)_afsim开源代码-CSDN博客blog.csdn.net/shengzimao/article/details/126787045