
二十一、day21
上一节学习了一个http服务器是如何实现的,以及每一步函数的实现过程。但上面大部分函数其实以及被封装好了,我们只需要调用就行了,今天跟着恋恋风辰大佬学习如何通过beast网络库快速搭建http服务器。
其实官网以及给出了如何通过beast快速搭建服务器的示例,可以参考boost官网“
Chapter 1. Boost.Beast - 1.86.0
视频参考:
C++ 网络编程(22) beast网络库实现http服务器_哔哩哔哩_bilibili
1. 头文件和作用域重命名
1 |
|
2. reponse时调用的一些函数
1 | namespace my_program_state { |
只封装两个函数,一个返回请求次数,一个返回当前的时间戳
3. http_connection
封装一个http_connection类用于处理 HTTP 请求和响应。负责接收客户端请求,解析请求内容,生成适当的响应,并将响应发送回客户端。同时,该类还管理连接的超时处理,确保长时间未响应的连接能够及时关闭
1 | class http_connection : public std::enable_shared_from_this<http_connection> { |
http_connection类继承std::enable_shared_from_this<T>模板类,便于使用shared_from_this()函数实现伪闭包。http_connection类成员变量的解释如下:
_buffer:定义一个缓存区,缓存区大小不超过
8k_request:构造一个请求头,类型为
http::request<http::dynamic_body>- dynamic_body:允许发送各种类型的请求
- string_body:只允许发文本类型的请求
_response:响应,同样也是dynamic_body类型
_deadline:定时器,用于异步操作时的超时控制或延时任务,使用的是
steady_timer定时器对象,即使系统时间被改变,定时器仍能够按照预期的时间触发- get_executor():获取于socket相关的执行器,也就是说,定时器和socket共享相同的IO线程资源
std::chrono::seconds(60):定时器在60s后被触发
成员函数的实现如下:
a. 构造函数
1 | http_connection(tcp::socket socket) : _socket(socket) {} |
该构造函数会报错,因为boost::asio::basic_stream_socket 类不支持复制构造。因此,在构造函数中尝试通过复制传递 socket 时,会发生编译错误,socket 只能通过移动语义来传递。
正确的构造函数如下:
1 | http_connection(tcp::socket&& socket) : _socket(std::move(socket)) {} |
为什么http_connection(tcp::socket socket)中按值传递不会调用复制构造函数,而是在初始化成员变量_socket(socket)时才调用复制构造函数?
http_connection(tcp::socket socket) 中的参数 socket 是按值传递的,这意味着它是从调用者那里“拷贝”进来的。由于 tcp::socket 禁止复制,但支持移动,所以编译器会自动尝试使用移动构造函数来初始化这个按值传递的参数。如果调用者传入的是一个临时对象(例如 std::move(socket) 或新创建的对象),那么这个按值传递的 socket 实际上是“移动”进来的,而不是复制进来的。
为什么仅在 _socket(socket) 这里出错?
在构造函数的初始化列表中,_socket(socket) 试图复制socket 参数,因为没有显式地使用 std::move。按值传递的参数 socket 本身是一个左值,要想移动它,必须显式地使用 std::move,将其转换为右值引用。这就是为什么必须在初始化列表中使用 std::move(socket)。
总结:
- 按值传递的 tcp::socket 是通过移动语义构造的,不会有问题。
- 但在初始化成员变量时,如果不显式使用 std::move,编译器会尝试复制 socket 参数,这是不允许的。因此,必须使用 std::move 使其变成右值,从而调用移动构造函数来初始化成员变量
除此之外,还有另外一种方式可以调用外界的socket,就是通过引用:
1)引用
引用绑定到已有的 socket 对象,并且始终指向这个对象,没有复制或移动。保证了在 http_connection 类中操作的 socket 与外部的 socket 是同一个对象,因此可以共享状态。
但是,由于 _socket 引用的是外部传入的对象,所以在 http_connection 对象的生命周期内,这个 socket 对象必须始终存在。如果 socket 对象被销毁了,引用就变成悬空引用,可能导致未定义行为。
1 | tcp::socket& _socket; |
2)移动构造函数
但如果我们像http_connection独立的管理connection,而不需要接收外界传递进来的socket,那么如何做?
1 | tcp::socket _socket; |
或者这样写
1 | tcp::socket _socket; |
其实 tcp::socket&& 和 tcp::socket 完全不一样,一个是按值传递,一个是右值引用,但因为socket中禁用了复制构造函数,允许移动,所以编译器会自动尝试使用移动构造函数来初始化这个按值传递的参数,所以这里都是相同的。但在其他时候,不能这样用,这两种传递完全不同。
| 特性 | 引用 (tcp::socket&) | 移动语义 (tcp::socket&&) |
|---|---|---|
| 对象所有权 | 由外部对象管理 | 由 http_connection 管理 |
| 效率 | 无复制或移动,效率高 | 通过移动语义高效转移对象所有权 |
| 生命周期依赖性 | 依赖于外部对象的生命周期 | 不依赖外部对象生命周期,自行管理 |
| 适用场景 | 适合共享已有对象并保证生命周期的一致性 | 适合 http_connection 需要完全控制 socket 对象 |
b. start()
1 | void start() { |
http_connection类就是负责服务器与客户端的联系,如果server接收到一个新的客户端连接,那么就创建一个http_connection对象,并调用start函数开始读客户端的请求。
其中,read_request()函数的实现如下
1 | void read_request() { |
调用异步读async_read函数从socket读取HTTP请求,数据存储至_buffer,解析后的数据存储至_request
- _socket: 表示与客户端的通信套接字,负责接收数据
- _buffer: 用于临时存储接收到的原始数据(未解析的字节流)
- _request: HTTP 请求对象,解析后的 HTTP 请求会存储在这个对象中
读取成功后调用lambda函数,因为async_read的回调函数中必须有error_code 和 bytes_transferred参数,但后者我们并没有在lambda函数体中使用到,为了避免编译器警告,通过boost::ignore_unused函数忽略该参数。当HTTP请求被成功读取后,调用process_request函数处理请求头。
1 | void check_deadline() { |
check_deadline() 通常用于实现超时处理。比如在一个网络服务中,客户端可能需要在一定时间内完成请求或响应。如果超过了这个时间(如60秒),定时器会触发,然后关闭客户端的连接。这样可以避免占用资源过久,确保服务器的稳定运行。
之前学的tcp是一个长连接,但今天学习的http是一个短连接,如果处理请求时间太长,我们应该主动将其连接断掉。
通过调用异步等待async_wait函数,用于等待定时器的超时事件发生。这个函数不会阻塞当前线程,而是让程序继续执行其他任务,当定时器时间到时,执行给定的回调函数。该回调函数用于关闭套接字,断开客户端与服务器的通信连接。
该函数还有另外一种写法,你觉得对吗?
1 | void check_deadline() { |
其实这个函数有风险存在,因为当调用check_deadline()时,需要过60s后判断超时后才会执行lambda函数,但是比如在58s在执行这个lambda函数时,http_connection因为某种原因(网络断开,引用计数减为0)被回收,那么lambda就会出错(this->_socket.close(ec);中this指向的空间发生了改变,那么这个close的执行是无效的,系统会崩溃)。所以必须将self传进来,让lambda捕获该参数,使其引用计数加一,实现伪闭包。
1 | auto self = shared_from_this(); // 伪闭包 |
还有,如果将self显式放在捕获列表中,那么无论是否在 lambda 体内使用,引用计数都会增加,因为捕获行为本身就会创建一个 shared_ptr 的拷贝。
注意【self】和【=】的区别,后者虽然也会捕获self,但如果在函数体没有使用到的话,编译器会优化,不让其创建实例。
c. process_request()
该函数用于处理不同的HTTP请求类型(GET或POST),并根据请求的具体方法生成相应的响应数据,返回给客户端。
1 | void process_request() { |
首先,将响应对象**_response的HTTP版本设置为与请求对象_request相同的版本。**HTTP 请求和响应都包含一个版本号,通常是 HTTP/1.1 或 HTTP/1.0,该操作确保响应与请求的协议版本匹配。
然后设置为短连接,keep_alive 用于决定是否启用长连接。在 HTTP/1.1 中,长连接允许客户端在同一个 TCP 连接上发送多个请求。
- false: 表示使用短连接,即在发送完响应后,服务器将关闭连接。
- true: 表示启用长连接,连接不会在响应后立即关闭,客户端可以继续发送更多请求。
最后,判断请求方法是GET还是POST。
如果请求方法是GET,那么
- 设置响应状态为
http::status::ok(200 OK),表示请求成功 - 设置响应头字段
server,其值为"Beast",表明服务器使用了Beast库 - 调用
create_response()来生成 GET 请求的响应数据(内容在create_response()中处理)
如果请求方法是POST,那么
- 设置响应状态为
http::status::ok,表示请求成功 - 同样设置
server字段 - 调用
create_post_response(),处理 POST 请求的特定逻辑
如果是未被明确处理的 HTTP 方法(如 PUT、DELETE 等),默认行为是
- 设置响应状态为
http::status::bad_request,表示这是一个无效请求 - 设置响应头字段
content-type为"text/plain",告知客户端响应的内容类型是纯文本 - 使用
beast::ostream(_response.body())向响应**_response**的正文中写入一条错误消息,说明这个请求使用了无效的 HTTP 方法,并附上具体的请求方法字符串
d. create_response()
该函数生成GET请求的响应数据。
1 | void create_response() { |
1)判断请求的URL目标路径是否为/count,表示客户端请求获取请求计数
- 在这种情况下,响应将设置内容类型为 text/html,表示返回的是一个 HTML 页面
- 然后通过
beast::ostream(_response.body())将 HTML 数据写入到响应的正文中,内容包括页面的标题Request count和请求计数 my_program_state::request_count()返回当前的请求计数,该值会被插入到响应的 HTML 中,显示在页面上
生成的HTML如下:
1 | <html> |
2)判断请求的URL目标路径是否为/time,表示客户端请求当前的系统时间
- 响应同样设置内容类型为 text/html
- 生成一个 HTML 页面,显示当前时间。时间通过
my_program_state::now()来获取,返回自 Unix 纪元以来的秒数
生成的HTML如下:
1 | <html> |
3)判断请求的URL目标路径既不是/count,也不是/time,则认为该资源不存在
- 设置响应状态为
http::status::not_found,即 HTTP 404 Not Found - 设置内容类型为 text/plain,表示返回的是纯文本
- 然后向响应正文写入一条简单的错误消息:File not found\r\n
e. create_post_response()
该函数处理客户端发送的 POST 请求,主要处理 /email 路径的请求,并解析接收到的 JSON 数据。函数根据收到的 POST 数据生成不同的响应。
1 | void create_post_response() { |
1)如果客户端发送的POST请求的目标路径是‘/email’:
- 读取并打印请求的 body: 从 _request.body() 中获取请求体数据(通常是客户端通过 POST 方式发送的内容),并将其转换为字符串格式,然后打印
- 设置响应的内容类型:服务器将返回 JSON 格式的响应,因此设置响应的 Content-Type 为 text/json
- 解析 JSON 数据:使用 Json::Reader 对请求体中的字符串进行 JSON 解析,解析 body_str 中的 JSON 数据,并将其存储在 src_root 中。如果解析失败,parse_success 将为 false。
- 如果解析失败,打印错误消息并构造带有错误码的 JSON 响应,比如
1 | { |
- 如果解析成功,从 src_root 中提取 email 字段,并打印它
- 构造返回的 JSON 响应,包含 email 和成功消息
- 最后,将 root 数据序列化为字符串并写入响应体中
返回的 JSON 响应内容类似于:
1 | { |
2)如果客户端的 POST 请求目标路径不是 /email,服务器返回 HTTP 404 Not Found 错误
f. write_response()
当系统解析完请求后并执行过GET/POST的相应操作生成响应后,执行write_response函数,将生成的 HTTP 响应异步写回客户端,并在发送完成后执行一些清理操作。
1 | void write_response() { |
首先,设置响应的 Content-Length,即响应正文的长度,表示服务器将要发送的内容大小,并将该长度赋值到 HTTP 头部的 Content-Length 字段。
然后,调用异步写函数将响应_response发送到客户端,发送完成后关闭连接:
- 关闭 TCP 连接的发送端,这意味着服务器已经完成了发送操作,但连接仍然可以用于接收数据
- tcp::socket::shutdown_send 表示只关闭发送端,而保留接收端未关闭。这是为了遵循 TCP 的四次挥手协议:客户端在接收到服务器的响应后,应关闭自己的发送端,并最终关闭整个连接
- 在调用 shutdown() 时遇到错误,错误信息会存储在 ec 中,但不做额外处理
最后,取消定时器,表示当前操作已经完成,不再需要超时检测了,这样可以防止超时处理逻辑错误地关闭仍然活跃的连接。
4. Server
为了方便,server直接写为一个函数,不封装为类
1 | void http_server(tcp::acceptor& acceptor, tcp::socket& socket) { |
调用async_accept函数异步等待客户端的连接,如果有新的连接,那么创建一个http_connection新实例,并调用start函数,读取客户端发送的请求头并执行相应操作。
5. 主函数
1 | int main() |
6. 测试
首先,从PostMan官网下载postman:
Download Postman | Get Started for Freewww.postman.com/downloads/
1)测试get
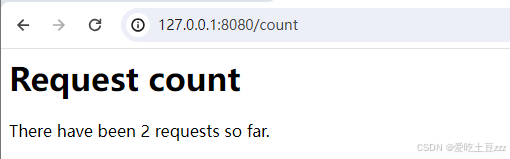
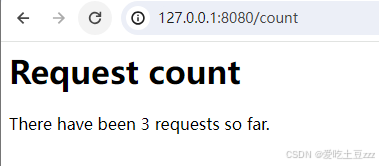
然后启动服务器并打开浏览器的新页面,输入‘127.0.0.1:8080/count’,测试get。
服务器成功返回数据,并展示位HTML页面,当刷新页面后,count也会相应的增加
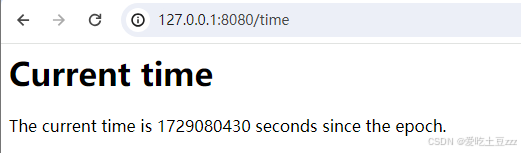
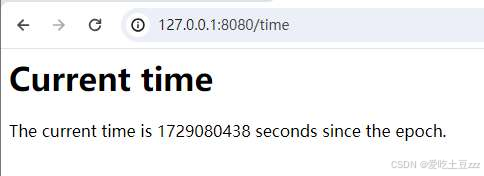
测试time,输入‘127.0.0.1:8080/time’,页面会显示当前的时间戳
2)测试post
打开postman,按照图片进行如下操作
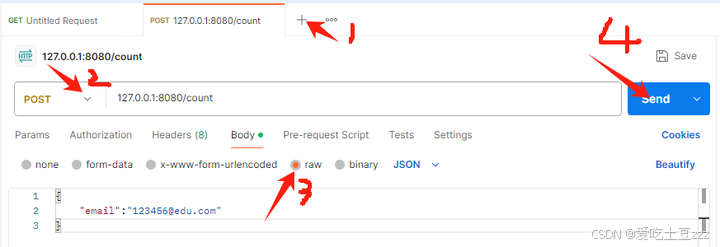
首先,创建一个新的请求,并设置位post,然后输入‘127.0.0.1:8080/email’,在raw中输入数据并点击发送
1 | { |
服务器返回相应数据
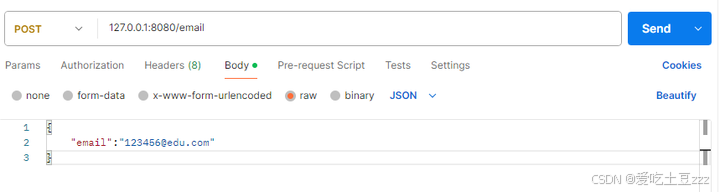
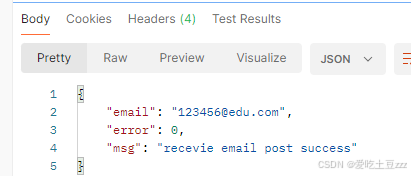
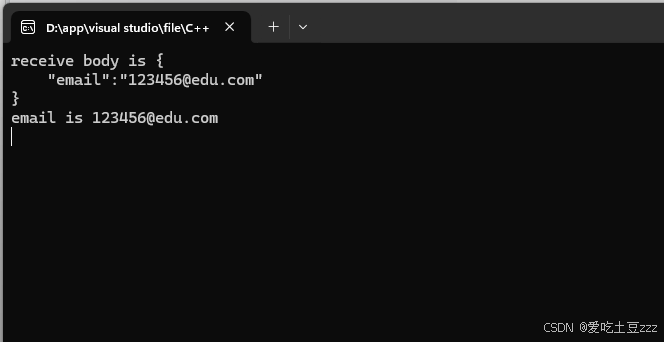
同时,服务器这里也打印处POST的相应数据
同理,也可以用postman做get测试,我这里就不再演示了