七、day7
这里使用博主恋恋风辰的原话:我对async的理解就是开辟一个一次性的线程执行并行任务,主线程可以通过future在合适的时机执行等待汇总结果。今天学习如何通过async、future、并行和函数式编程实现快速排序提高计算效率。
- 函数式编程:指一种编程风格,函数调用的结果完全取决于参数,而不依赖任何外部状态。举个例子,若我们以相同的参数调用同一个函数两次,结果会完全一致。
参考:
快速排序
up主恋恋风辰个人博客
up主[mq白的代码仓库](ModernCpp-ConcurrentProgramming-Tutorial/README.md at main · Mq-b/ModernCpp-ConcurrentProgramming-Tutorial)
1. 快速排序
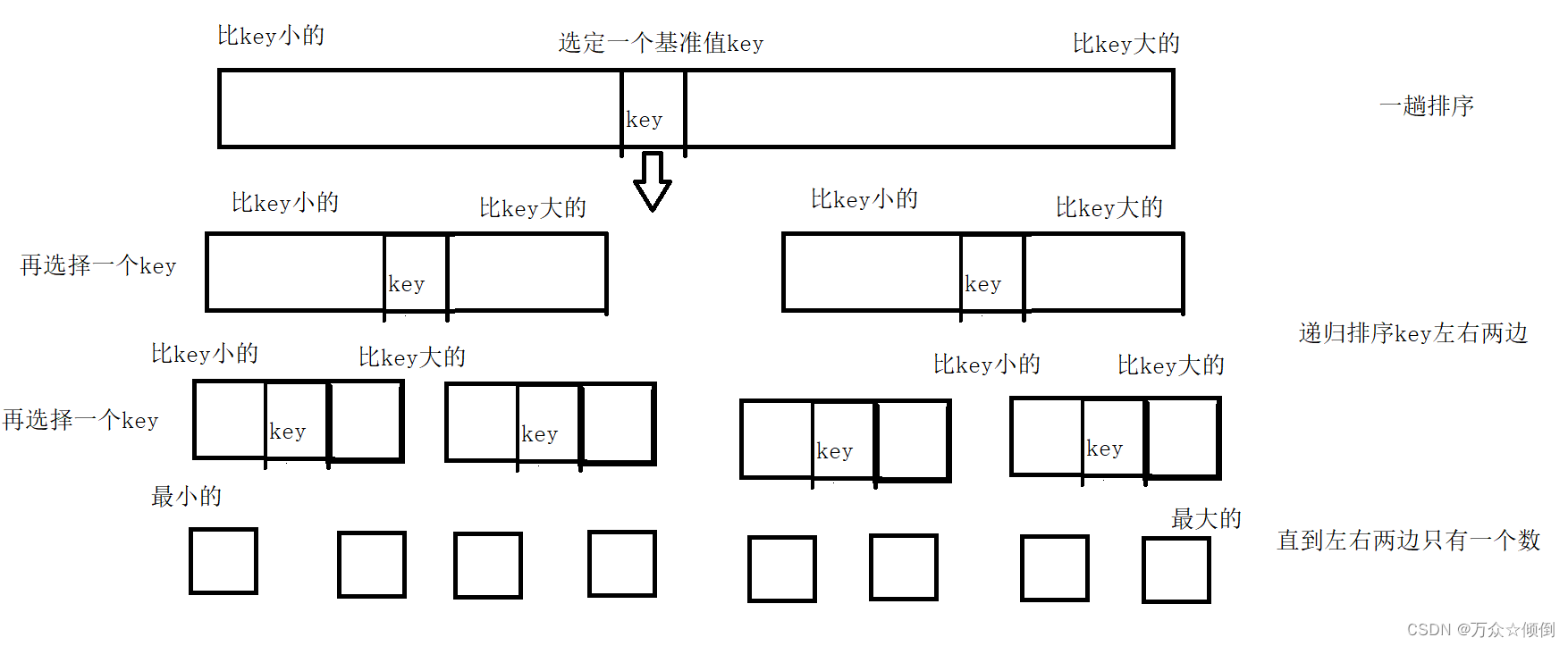
快速排序是一种高效的排序算法,采用分治法的思想进行排序。以下是快速排序的基本步骤:
- 选择一个基准元素(pivot):从数组中选择一个元素作为基准元素。选择基准元素的方式有很多种,常见的是选择数组的第一个元素或最后一个元素。
- 分区(partitioning):重新排列数组,把比基准元素小的元素放在它的左边,把比基准元素大的元素放在它的右边。在这个过程结束时,基准元素就处于数组的最终位置。
- 递归排序子数组:递归地对基准元素左边和右边的两个子数组进行快速排序。
如下图所示:

图片来源:https://blog.csdn.net/qq_61422622/article/details/131667258
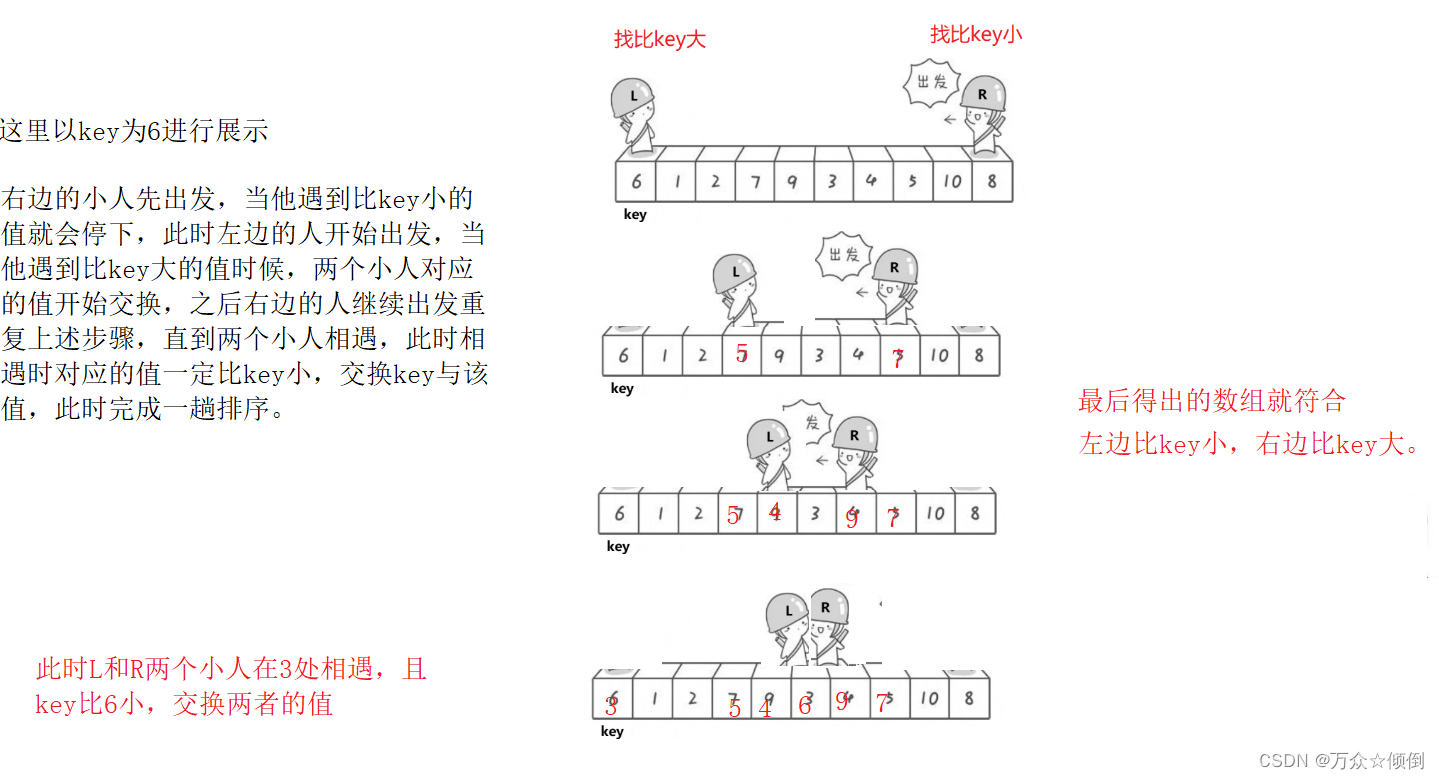
要想了解整个排序过程的实现,首先我们必须明白单趟排序的实现:
图片来源:https://blog.csdn.net/qq_61422622/article/details/131667258
注意:左边小人开始出发时是从key处开始的,如果右边停止左边出发时,左边找不到比key大的直接相遇了,也是直接交换。 这里先出发的顺序可以是左,也可以是右边。
- 左边为key,右边先走,相遇值比key小
- 右边为key,左边先走,相遇值比key大
为什么相遇位置一定比基准值小或者和基准值相同(左边为key)?这是因为:
- 右指针始终会跳过所有比基准值大的元素,直到它找到了一个比基准值小的元素。
- 左指针始终会跳过所有比基准值小的元素,直到它找到了一个比基准值大的元素。
所以,当左右指针相遇时,右指针所指向的元素就是比基准值小的,并且是因为右指针先走的,而且当右指针找到比key小的值时就会停下来,此时左指针才会走。当左指针和右指针相遇时,必须停止,此时就算左指针指向的相遇值并没有比key大,但肯定比key小(右指针先停,所以肯定比key小),所以可以直接和第一个元素进行交换,因为比key小的值要放在key左边。
那么如果两个小人通过移动进行一次交换之后,第二次右指针先移动(比如上图交换5和7之后,假如右指针直接和左指针指向的值‘5’相遇了),但是并没有找到比key小的值,直接和左指针相遇了,相遇点肯定比key小。因为在第一轮时,左指针必须找到比key大的值才会停止,而且停止之后会和右指针进行交互,交换之后左指针指向的值其实是比key小的(从右指针交换过来)。因为相遇点肯定比key小,所以可以直接和key进行交换。
因此,相遇的位置必然是基准值所在的位置,或者是比基准值小的位置。
代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
template<typename T>
void quick_sort_recursive(T arr[], int start, int end) {
if (start >= end) return;
T key = arr[start];
int left = start, right = end;
while(left < right) {
while (arr[right] >= key && left < right) right--;
while (arr[left] <= key && left < right) left++;
std::swap(arr[left], arr[right]);
}
if (arr[left] < key) {
std::swap(arr[left], arr[start]);
}
quick_sort_recursive(arr, start, left - 1);
quick_sort_recursive(arr, left + 1, end);
}
template<typename T>
void quick_sort(T arr[], int len) {
quick_sort_recursive(arr, 0, len - 1);
}
|
2. 函数式编程
上面说到了,函数式编程就是用相同的参数调用同一个函数多次,结果完全一致的一种编程风格。
我们通过函数式编程修改上面的快速排序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| template<typename T>
std::list<T> sequential_quick_sort(std::list<T> input)
{
if (input.empty()){
return input;
}
std::list<T> result;
result.splice(result.begin(), input, input.begin());
T const& pivot = *result.begin();
auto divide_point = std::partition(input.begin(), input.end(),
[&](T const& t) {return t < pivot; });
std::list<T> lower_part;
lower_part.splice(lower_part.end(), input, input.begin(),
divide_point);
auto new_lower(
sequential_quick_sort(std::move(lower_part)));
auto new_higher(
sequential_quick_sort(std::move(input)));
result.splice(result.end(), new_higher);
result.splice(result.begin(), new_lower);
return result;
}
|
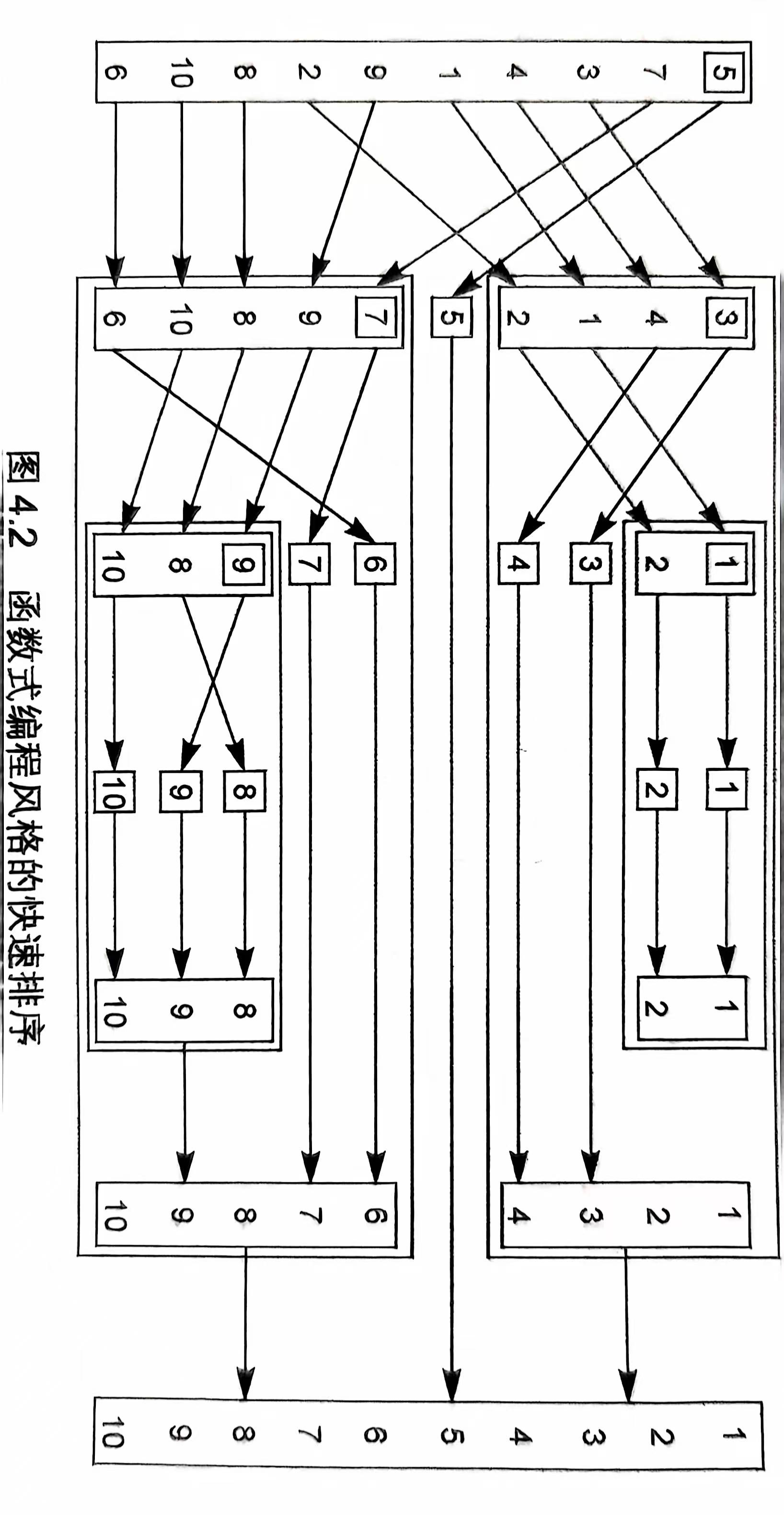
代码解释:由列表给出一列乱序数值,我们从中选取一个作为”基准元素“,把整个列表分成两组——一组的值比基准元素小,另一组的值大于等于基准元素;再将这两个分组排序,各自得出新的有序列表,作为结果返回,然后依次拼接;先是小值的有序列表,接着是基准元素,最后是大值的有序列表,由此得到原列表的排序后的副本。
std::partition():partition() 的行为不是排序,而是整理。列表中的一些元素令 lambda 函数返回true(满足条件),partition() 以此为准,将他们置于列表前半部分,而其余元素则使 lambda 函数返回false,遂置于后半部分,仅此而已,前后两部分的元素并未排序。
以含有10个整数的乱序列表为例,如下图:
图片来源:C++并发实战编程(第2版)
3. 并行排序
其实快速排序相当于将一个乱序列表分成两个部分,每个部分的元素要么都比基准值大,要么都比基准值小,然后递归对这两个部分再次排序,两个部分分成四个部分……
那么既然处理的任务都相同,都是进行排序,我们能否使用并行的手段处理数据呢?
我们仔细看,在函数式编程排序过程中,将比基准值小的子列表单独拿出来,而将比基准值大的子列表在原列表input内继续修改。唯一干扰的情况下是,后面子列表做并行排序的时候,前面子列表也在排序,会整体修改这个input。所以我们将列表的前半部分(小于基准值)不再由当前线程执行,而是通过async在另一线程上并行操作。链表的后半部分依然按串行直接递归的方式排序。
因为是两部分都会递归运行,所以如果async每次都能开启新线程,那么只要递归三层,就会有8个线程同时运行;如果递归10层,将有1024个线程同时运行(如果系统硬件不能承受这个数量的运行,async的默认调用策略就不会生成新的线程,参考上一节)。
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
template<typename T>
std::list<T> parallel_quick_sort(std::list<T> input)
{
if (input.empty()){
return input;
}
std::list<T> result;
result.splice(result.begin(), input, input.begin());
T const& pivot = *result.begin();
auto divide_point = std::partition(input.begin(), input.end(),
[&](T const& t) {return t < pivot; });
std::list<T> lower_part;
lower_part.splice(lower_part.end(), input, input.begin(),
divide_point);
std::future<std::list<T>> new_lower(
std::async(¶llel_quick_sort<T>, std::move(lower_part)));
auto new_higher(
parallel_quick_sort(std::move(input)));
result.splice(result.end(), new_higher);
result.splice(result.begin(), new_lower.get());
return result;
}
|
4. 使用线程池排序
同时我们也可以使用线程池的方式对前半部分排序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
template<typename T>
std::list<T> thread_pool_quick_sort(std::list<T> input)
{
if (input.empty())
{
return input;
}
std::list<T> result;
result.splice(result.begin(), input, input.begin());
T const& pivot = *result.begin();
auto divide_point = std::partition(input.begin(), input.end(),
[&](T const& t) {return t < pivot; });
std::list<T> lower_part;
lower_part.splice(lower_part.end(), input, input.begin(),
divide_point);
auto new_lower = ThreadPool::commit(¶llel_quick_sort<T>, std::move(lower_part));
auto new_higher(
parallel_quick_sort(std::move(input)));
result.splice(result.end(), new_higher);
result.splice(result.begin(), new_lower.get());
return result;
}
|