十一、day11
上一节中,我们简单学习了有关内存次序的六种内存次序和三种内存模型,今天学习原子类型中的同步和先行关系,为下一节六种内存序和三种模型的实现打好基础。
今天学习的内容包括:
- 可见性是指什么?
- 什么是先行关系;
- 单线程和多线程下的几种先行关系总结;
- 先行关系并不是指指令执行顺序;
参考:
1. 可见
可见 是 C++ 多线程并发编程中的一个重要概念,它描述了一个线程中的数据修改对其他线程的可见程度。具体来说,如果线程 A 对变量 x 进行了修改,那么其他线程 B 是否能够看到线程 A 对 x 的修改,就涉及到可见的问题。
C++ 标准中的可见:
- 如果线程 A 对变量 x 进行了修改,而线程 B 能够读取到线程 A 对 x 的修改,那么我们说线程 B 能看到线程 A 对 x 的修改。也就是说,线程 A 的修改对线程 B 是可见的。
C++ 标准通过内存序(memory order)来定义如何确保这种可见,而不必直接关心底层的 CPU 和编译器的具体行为。内存序提供了操作之间的顺序关系,确保即使存在 CPU 重排、编译器优化或缓存问题,线程也能正确地看到其他线程对共享数据的修改。
例如,通过使用合适的内存序(如 memory_order_release 和 memory_order_acquire),可以确保线程 A 的写操作在其他线程 B 中是可见的,从而避免数据竞争问题。
总结:
- 可见 关注的是线程之间的数据一致性,而不是底层的实现细节。
- 使用 C++ 的内存序机制可以确保数据修改的可见,而不必过多关注具体的 CPU 和编译器行为。
这种描述方式可以帮助更清楚地理解和描述多线程并发编程中如何通过 C++ 标准的内存模型来确保线程之间的数据一致性,而无需太多关注底层细节。
但是在大多数的情况下,多线程代码并不会主动的使用内存序,一般都是互斥量、条件变量等同步手段,这些手段是否存在可见性的问题?
没问题,这些手段会自动确保数据的可见性。例如, std::mutex 的 unlock() 保证:
- 此操作同步于任何后继的取得同一互斥体所有权的锁定操作。
也就是 unlock() 同步于 lock()。
“同步于”:操作 A 的完成会确保操作 B 在其之后的执行中,能够看到操作 A 所做的所有修改。
也就是说:
std::mutex的unlock()操作同步于任何随后的lock()操作。这意味着,线程在调用unlock()时,对共享数据的修改会对之后调用lock()的线程可见。
其他的同步手段也大体类似这样的思想。
六种内存序来自枚举类型std::memory_order:
1 | typedef enum memory_order { |

这 6 个常量,每一个常量都表示不同的内存次序。
大体来说我们可以将它们分为三类(不是根据原子操作的类型分的)。
memory_order_relaxed宽松次序:不是定序约束,仅对此操作要求原子性。memory_order_seq_cst先后一致次序,这是库中所有原子操作的默认行为,也是最严格的内存次序,是绝对安全的。- 剩下的四种内存序属于获取-释放次序。
2. 同步与先行
直接说同步与先行是什么,有什么关系,可能会不太好理解。我们通过一个例子来解释:
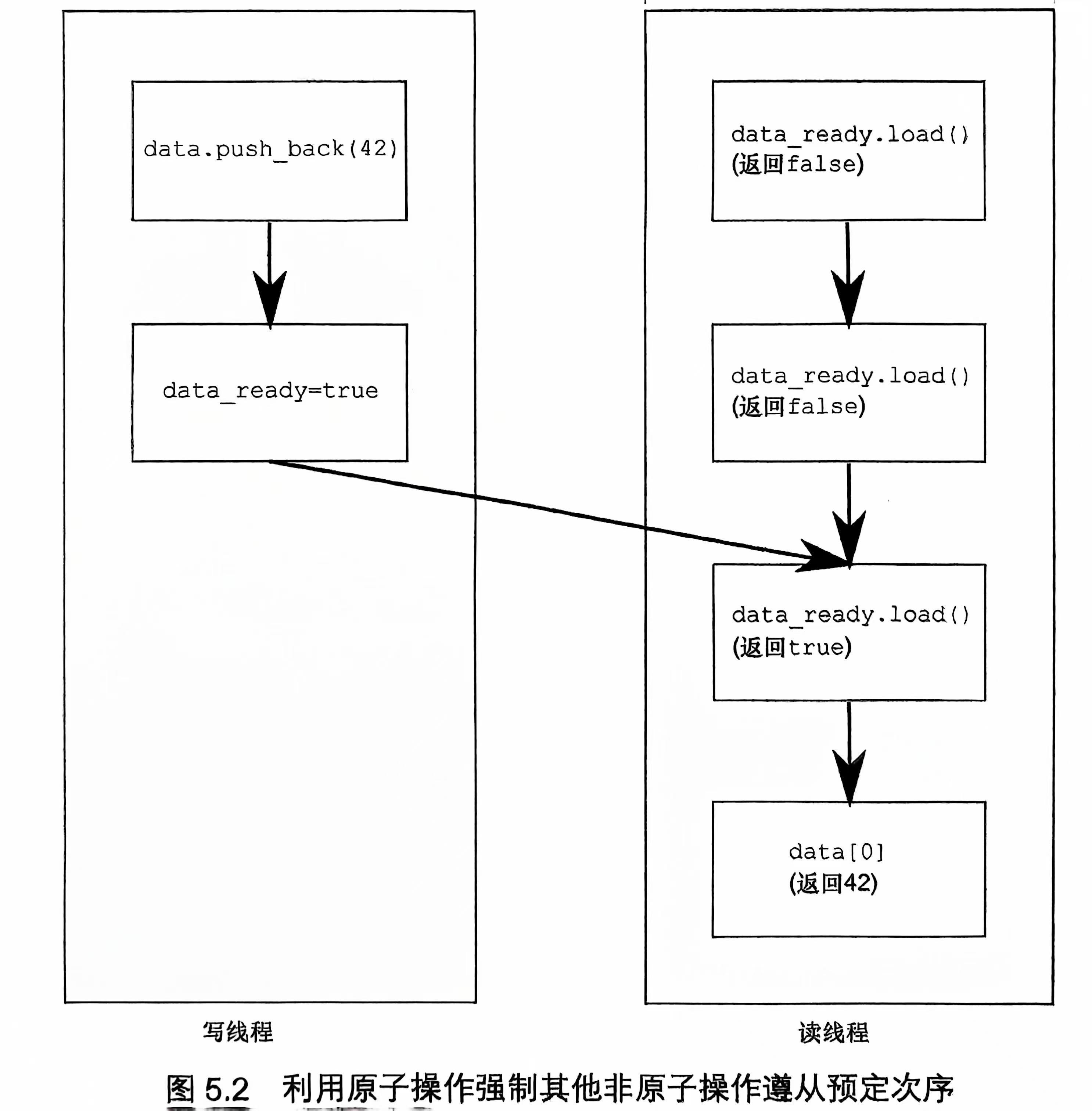
假设现在有两个线程共同操作一个数据结构,写线程设置一个标志,用以表示数据已经存储妥当,而读线程则一直待命,等到标志成立才着手读取,代码如下:
1 |
|
我们以循环的方式等待类型为std::atomic<bool>的变量data_ready为true(暂且忽略其效率低下)。但是在一份数据上进行非原子化或无同步手段的读②和写③,会导致未定义行为,因此我们必须为其施加某种次序,确保强制这些访问服从一定的顺序。
我们定义的变量data_ready其实就是一个简单的强制次序,通过两种内存模型关系“先行(happend-before)”和“同步(synchronizes-with)”,确定了必要的次序。数据写③在标志位data_ready设置成true④之前发生,标志判别①在数据读②之前发生。若标志位data_ready的值为true成立①,写操作与读操作达成同步,构成先行关系,即写③只能在读②之前完成。写操作③在设置标志位data_ready为true④之前发生,且④在从标志位data_ready调用load函数读取到true值①之前发生,而①又在读操作②之前发生,又因为先行关系可以传递,所以这些操作被强制施加了预定的次序:③→④→①→②,即写操作③总要在读操作②之前完成。如下图所示
通过上面的解释,我们应该对“同步”和“先行”有了一个简单的了解,接下来详细说一下二者的概念。
2.1 同步关系(synchronizes-with)
原子操作可以隐式地形成同步关系(synchronizes-with),但同步关系不限于原子操作,还可以通过其他机制(如互斥锁、条件变量等)实现。但这些同步机制其实都是对原子操作的模拟,所以这句话也可以说为:同步关系只存在于原子类型的操作之间。
同步关系的基本思想是:对变量 x 执行原子写操作 W 和原子读操作 R,且两者都有适当的标记(六种内存序)。只要满足下面其中一点,它们即彼此同步:
- R 读取了 W 直接存入的值。
- W 所属线程随后还执行了另一原子的写操作, R 读取了后面存入的值。
- 任意线程执行一连串 “读-改-写” 操作(如fetch_add或compare_exchange_weak(),前者相当于x++,后者相当于“比较-交换-返回”),而其中第一个操作读取的值由 W 写出。
上面的代码段符合第一点,先写后读,读到的数据必定是先写入的,所以是同步的。
“synchronizes-with“ : 同步,“A synchronizes-with B” 的意思就是 A和B同步,简单来说如果多线程环境下,有一个线程先修改了变量m,我们将这个操作叫做A,之后有另一个线程读取变量m,我们将这个操作叫做B,那么B一定读取A修改m之后的最新值。也可以称作 A “happens-before“ B,即A操作的结果对B操作可见。
2.2 先行关系(happend-before)
先行关系(happend-before)和严格先行(strongly-happens-before)关系是在程序中确立操作次序的基本要素;它们的作用:界定哪些操作能看见其他哪些操作产生的结果(并不是说哪些操作一定在哪些操作之前发生)。这种关系在单一线程中非常直观,在代码中,如果操作A的语句位于操作B之前,那么A就先于B发生,且A严格先于B发生(也可以理解为,如果操作A先行于操作B,那么操作A的结果对操作B可见)。但是,如果同一语句内出现多个操作(一个’;’组成一个语句),则它们之间通常不存在先行关系,因为C++标准没有规定执行次序。比如:
1 | void foo(int a, int b) { |
在上述代码中,一条语句中出现了多个操作(调用了两次get_num()并将结果作为实参传入foo函数),因两次调用 get_num() 的次序不明(C++标准没有规定多个操作的执行次序,它们之间不存在控制流程的先后关系,因而也没有先行关系),代码输出的结果有两种:“1,2”或“2,1”。
上面的规则实质上是单线程的顺序先行(sequenced-before),而在多线程中可以理解为线程间先行关系(inter-thread-happens-before):若某一线程执行操作A,另一线程执行操作B,从跨线程视角观察,操作A先于操作B发生,则操作A先行于操作B。
操作A先行于操作B,并不是说操作A一定会在操作B之前发生,而是表示如果操作A在操作B之前发生,那么操作A的结果一定对操作B可见。
线程间先行关系是可以传递的:若操作A跨线程地先于操作B发生,且操作B跨线程地先于操作C发生,则操作A跨线程地先于操作C发生。就像我们在引入同步和先行关系的代码中一样:因为③→④→①→②,所以③先行于②。
所以,如果我们要在某一个线程上改动多个数据,且要令这些改动能被另一线程的后续操作可见,我们只需为这两个线程确立一次同步关系即可。
我们在说先行关系的概念时提到了严格先行关系,那么它又是什么呢?
其实严格先行关系于先行关系基本相同,上面关于先行关系的规则同样适用于严格先行关系:若操作A于操作B同步,或操作A按流程顺序在操作B之前发生,那么操作A严格地在操作B之前发生。同样,严格先行关系也适用于传递规律。但是,二者有一点不同:在线程间先行关系和先行关系中,各种操作都被标记为 memory_order_consume(六种内存序之一),而严格先行关系则无此标记。由于大多数代码多不会使用该标记,所以二者其实都可以综合理解为同一个“先行关系”。
2.2.1 Happens-before不代表指令执行顺序
先行并不代表指令实际执行顺序,就像上面说的一样:操作A先行于操作B,并不是说操作A一定会在操作B之前发生,而是表示如果操作A在操作B之前发生,那么操作A的结果一定对操作B可见。比如:
1 | int Add() { |
在单线程下,虽然在代码中,指令A确实在指令B前面(A顺序先行B),则指令A确实先行于指令B,如果A先执行了,那么A的结果一定对B可见。但是计算机的指令可能不是按这样的顺序执行,一条C++语句对于多条计算机指令:有可能是先将b值放入寄存器eax做加1,再将a的值放入寄存器edx做加1,然后再将edx寄存器的值写回a,将eax写回b。
因为对于计算机来说 1处 操作和 2处 操作的顺序对于 3处 来说并无影响。只要3处返回a+b之前能保证a和b的值是增加过的即可。
那我们语义上的”Happens-before”有意义吗? 是有意义的,因为如果 a 顺序先行于 b,那么无论指令如何编排,最终写入内存的顺序一定是a先于b(比如单核最后将数据放入Memory缓存中,顺序一定是a先于b)。
再举一个例子,通过汇编说明:
1 | int A, B; |
如果在不使用优化的情况下编译,gcc foo.c -S,foo函数中针对A和B操作的汇编代码如下:
1 | movl B(%rip), %eax |
即先把变量B的值赋给寄存器eax,将寄存器eax加一的结果赋值给变量A,最后再将变量B置为0。
而如果使用O2优化编译,代码重排,gcc foo.c -S -O2 则得到下面的汇编代码:
1 | movl B(%rip), %eax |
即先把变量B的值赋给寄存器eax,然后变量B置零,再将寄存器eax加一的结果赋值给变量A。
这个步骤就和代码中的执行顺序不符合。其原因在于,foo函数中,只要将变量B的值暂存下来,那么对变量B的赋值操作可以被打乱而并不影响程序的执行结果,这就是编译器可以做的重排序优化。
以微信群聊消息为例子说明这个问题。假设有多人在群里聊天,如果A说的消息1与B说的消息2之间,没用明确的先后顺序,比如消息1是回复或者引用了消息2的话,那么其实在整个群聊视图里面,两者的先后顺序如何是无关紧要的。即参与群聊的两个用户,其中一个用户可能看到消息1在消息2之前,另一个用户看到的顺序相反,这都是无关大局的,因为两个消息之间没有关系。
1. Happens-before 的意义是什么?
Happens-before 在程序设计中起到了逻辑约束的作用,规定了操作之间的可见性和一致性:
- 如果操作 A 先行发生于操作 B:
- 保证 A 的效果对 B 可见,即 B 必须观察到 A 的修改。
- 保证乱序不会破坏逻辑顺序:程序在最终写入共享内存时,A 的修改必须“先于” B 的修改,即使在执行过程中,操作 A 和 B 的指令被重排,只要 A 先行发生于 B,最终写入内存的顺序依然是 A 的结果先生效,然后是 B 的结果。
- 保证数据一致性:当一个线程观察到 A 的效果时,它必然也能观察到 A 之前所有操作的效果。
2. 指令乱序执行的背景?
现代 CPU 和编译器会对指令进行重排序,以提高性能:
- 编译器可能重新排列指令以优化寄存器或流水线使用。
- CPU 的硬件可能在执行时动态调整指令的顺序。
然而,这种乱序不会破坏程序的语义,因为 Happens-before 提供了一个逻辑上的约束,确保即使指令被重排,最终的行为仍符合程序员的预期。
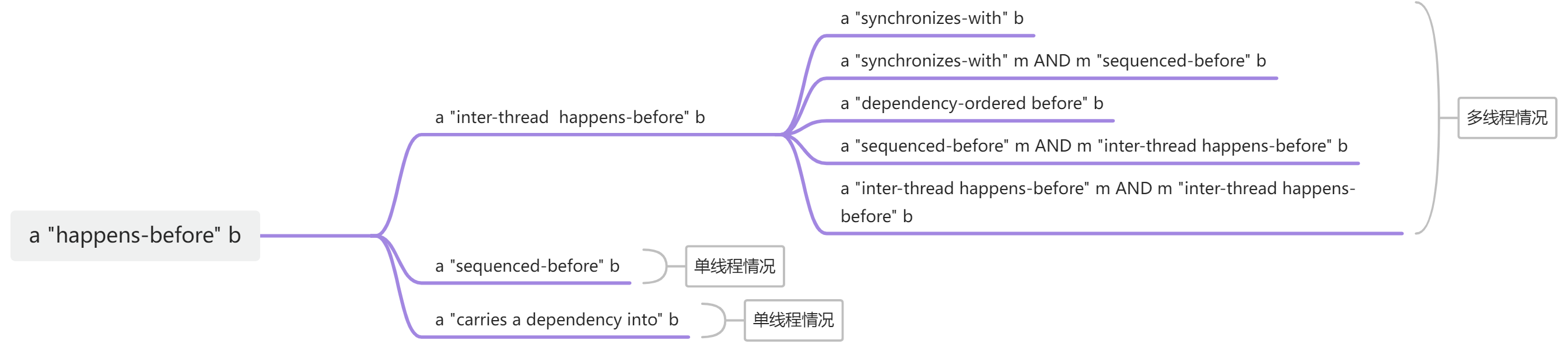
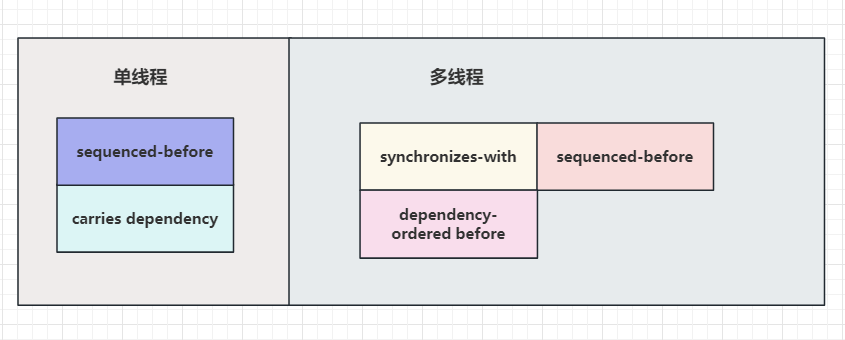
2.2.2 先行关系总结
单线程下
单线程情况下前面的语句先执行,后面的语句后执行。操作a先于操作b,那么操作b可以看到操作a的结果。我们称操作a顺序先行于操作b。也就是”a sequenced-before b”,也可以称为”a happens before b”。比如
1
2
3
4
5
6int main(){
//操作a
int m = 100;
//操作b
std::cout << "m is " << std::endl;
}操作a在操作b前执行,也就是说操作a顺序先行于操作b,即操作a先行于操作b,所以操作a的结果对操作b可见,操作b可读到m的值。
“sequencde-before”具备传递性,假如操作 a “sequenced-before” 操作 b, 且操作 b “sequenced-before” 操作 c, 则操作 a “sequenced-before” 操作 c。

多线程下
多线程间的先行也叫做线程间先行(inter-thread-happens-before):若某一线程执行操作A,另一线程执行操作B,从跨线程视角观察,操作A先于操作B发生,则操作A先行于操作B。这是多线程情况下的先行(happens-before)。
我们前面提到的”synchronizes-with” 可以构成 “happens-before”。如果线程 1 中的操作 a “synchronizes-with” 线程 2 中的操作 b, 则操作 a “inter-thread happens-before” 操作 b。
此外 synchronizes-with 还可以 “后接” 一个 sequenced-before 关系组合成 inter-thread happens-before 的关系:
比如操作 a “synchronizes-with” 操作 b, 且操作 b “sequenced-before” 操作 c, 则操作 a “inter-thread happens-before” 操作 c。
同样的道理, Inter-thread happens-before 关系则可以 “前接” 一个 sequenced-before 关系以延伸它的范围; 而且 inter-thread happens-before 关系具有传递性:
- 如果操作 a “sequenced-before” 操作 k, 且操作 k “inter-thread happens-before” 操作 b, 则操作 a “inter-thread happens-before” 操作 b:
如果操作 a “inter-thread happens-before” 操作 k, 且操作 k “inter-thread happens-before” 操作 b, 则操作 a “inter-thread happens-before” 操作 b:





2.3 依赖关系
依赖关系有 carries dependency 和 dependency-ordered before。单线程情况下,操作A顺序先行于操作B,且操作B依赖于操作A的数据,则称操作A “carries a dependency into” 操作B,或操作A将依赖关系带给B,或操作B依赖于操作A。
1 | void TestDependency() { |
在该段代码中,函数打印str[i]的值,但是在 3 处,数据依赖于 1 处和 2 处两个变量的值,达成依赖关系。
在单线程下执行该函数,那么1 顺序先行于 3,且 3 依赖于 1 的数据,则 1 “carries a dependency into” 3;同理,2 “carries a dependency into” 3。
“carries a dependency into” 也被归为”happens-before”。

在多线程下,线程 1 执行操作A(i++),线程 2 执行操作B(根据变量 i 访问字符串下的元素)。如果线程 1 先于线程 2 执行,且操作A的结果对操作B可见,那么称操作A dependency-ordered before” 操作B。其实可以理解为A 和 B 是同步的,只不过A “dependency-ordered before” B 更细化一点,表述了一种依赖,比如操作A仅仅对i增加,而没有对字符串修改。而操作B需要通过i访问字符串数据。那操作B实际上是依赖于A的。
2.4 总结
单线程和多线程下的先行关系可以总结为: