
十二、day12
在前两节中(并发编程(10)和并发编程(11)),我们简单学习了有关内存次序的六种内存次序和三种内存模型,并对C++同步和先行关系进行了详细的了解。今天学习六种内存序的使用方法以及三种模型是如何实现的。简单回顾一下上上节中我们解到的知识:
- 内存次序操作包括顺序一致性、强制顺序、弱顺序;
- 枚举类
std::memory_order中定义了六种宏,方便我们在使用原子类型操作时将其作为额外参数加入; - 六种内存序按原子类型的操作被划分为:存储操作,载入操作,“读改写”操作;
- 六种内存序相互组合可以实现三种顺序模型:
Sequencial consistent ordering、Acquire-release ordering、Relaxed ordering。 - 六种内存序可以分为三类(不是根据原子操作的类型分的):宽松次序(memory_order_relaxed)、先后一致次序(memory_order_seq_cst)、获取-释放次序(剩余四种)
接下来的内容要求我们对上一节的内容必须掌握,即必须对什么是先行、同步以及先行的几种熟悉要有一定的了解,不然你可能会看的云里雾里。
接下来对内存次序和内存模型的实现进行详细分析。
参考:
- 博主恋恋风辰的个人博客
- C++六种内存序详解 - ling_jian - 博客园
- 如何理解 C++11 的六种 memory order? - 知乎
- up主mq白cpp的个人仓库
- C++11中的内存模型下篇 - C++11支持的几种内存模型 - codedump的网络日志
1. CPU 内存结构
一个简单的四核CPU内存结构示意图如下所示:
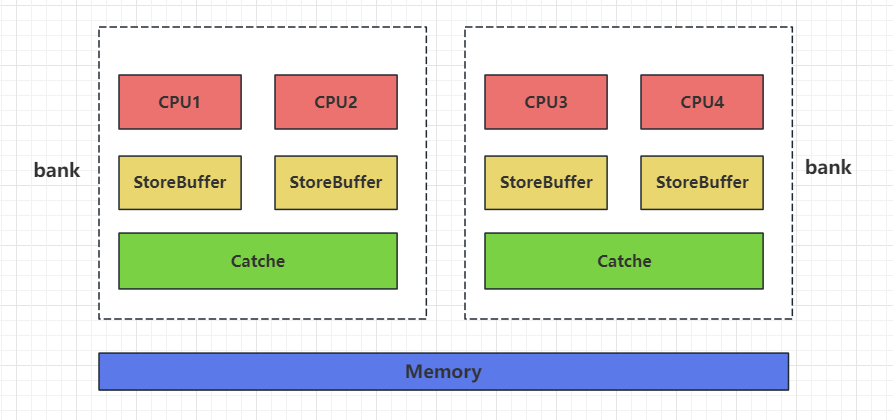
CPU 和内存之间通过三级缓存(StoreBuffer、Cache、Memory)进行数据交互,CPu每个核都有自己的缓存区StoreBuffer,对其他核不可见。但是每两个核组成一个Bank,每个Bank共享一个Cache缓存区,每个Bank中的核可以将缓存区StoreBuffer中的数据写入至Cache,这样两个核之间的数据就可以进行交互。每四个核又有一个缓存区Memory,每个Bank可以将自己的Cache写入至Memory,这样两个Bank,即四个核就可以进行数据交互。
如果多个核对同一个快缓存区的数据进行修改,比如对Cache缓存区中的变量a进行值修改,可能会造成数据竞争,那该如何保证数据一致性?这就要提及MESI一致性协议。
MESI 协议,是一种叫作写失效(Write Invalidate)的协议。在写失效协议里,只有一个 CPU 核心负责写入数据,其他的核心,只是同步读取到这个写入。在这个 CPU 核心写入 cache 之后,它会去广播一个“失效”请求告诉所有其他的 CPU 核心。
MESI 协议对应的四个不同的标记,分别是:
- M:代表已修改(Modified),用来告诉其他核已经修改完成,其他核可以向cache中写入数据。
- E:代表独占(Exclusive),表示数据只是加载到当前 CPU核 自己的store buffer中,其他的核并没有加载对应的数据到自己的 store buffer 里。这个时候,如果要向独占的 store buffer 写入数据,我们可以自由地写入数据,而不需要告知其他 CPU 核。
- S:代表共享(Shared),共享状态就是在多核中同时加载了同一份数据。所以在共享状态下想要修改数据要先向所有的其他 CPU 核心广播一个请求,要求先把其他 CPU 核心里面的 cache ,都变成无效的状态,然后再更新当前 cache 里面的数据。
- I:代表已失效(Invalidated)
我们可以这么理解,如果变量a此刻存在于各个核的StoreBuffer中,那么CPU1核修改这个a的值,放入cache时通知其他CPU核写失效,因为同一时刻仅有一个CPU核可以写数据,但是其他CPU核是可以读数据的,那么其他核读到的数据可能是CPU1核修改之前的。
2. 先后一致次序
- 先后一致次序就是
std::memory_order_seq_cst,这是库中所有原子操作的默认行为,也是最严格的内存次序,是绝对安全的。 - 该内存序实现了内存模型
Sequencial consistent ordering - 适用操作:读(
load)、写(store)、读改写(read-modify-write)。
2.1 什么是Sequencial consistent
直观上,读操作应该返回写操作“最后”一次写入的值。
- 在单处理器系统(单线程)中,“最后”由程序次序定义。
- 在多处理器系统(多线程)中,我们称之为顺序连贯(sequential consistency, SC).
通俗地说,SC要求所有内存操作表现为(appear)逐个执行(任一次的执行结果都像是所有处理器的操作都以某种次序执行),每个处理器中的操作顺序都以其程序指定的顺序执行。SC有两点要求:
- 每个处理器的执行顺序和代码中的顺序(program order)一样。
- 在所有处理器间,所有处理器都只能看到一个单一的操作执行顺序。对于写操作W1, W2, 不能出现从处理器 P1 看来,执行次序为 W1->W2; 从处理器 P2 看来,执行次序却为 W2->W1 这种情况。
- 这使得内存操作需要表现为原子执行(瞬发执行):可以想象系统由单一的全局内存组成,每一时刻,由switch将内存连向任意的处理器,每个处理器按程序顺序发射(issue)内存操作。这样,switch就可以提供全局的内存串行化性质。换大白话来说,就是所有线程的内存操作都必须以某种全局顺序执行,并且该顺序对所有线程可见,并符合每个线程的程序顺序。
我们以微信中的群聊消息作为例子说明SC的这两个要求。在这个例子中,群聊中的每个成员,相当于多核编程中的一个处理器,那么对照顺序一致性的两个要求就是:
- 每个人自己发出去的消息,必然是和ta说话的顺序一致的。即用户A在群聊中依次说了消息1和消息2,在群聊天的时候也必然是先看到消息1然后再看到消息2,这就是前面SC第一个要求。
- 群聊中有多个用户参与聊天(多处理器),如果所有人看到的消息顺序都一样,那么就满足了前面顺序一致性的第二个要求了,但是这个顺序首先不能违背前面的第一个要求。
SC作为默认的内存序,是因为它意味着将程序看做是一个简单的序列。如果对于一个原子变量的操作都是顺序一致的,那么多线程程序的行为就像是这些操作都以一种特定顺序被单线程程序执行。它不仅保证了单个原子变量操作的全局顺序,而且保证了所有使用顺序一致性内存序的原子变量之间的操作顺序在所有线程的观测中是一致的。
而非顺序一致内存次序(non-sequentially consistency memory ordering)强调对同一事件(代码),不同线程可以以不同顺序去执行,不仅是因为编译器可以进行指令重排,也因为不同的 CPU cache 及内部缓存的状态可以影响这些指令的执行。但所有线程仍需要对某个变量的连续修改达成顺序一致。
我们通过宽松次序和先后一致次序的对比进而说明后者的作用:
1 | std::atomic<bool> x, y; |
该段代码通过宽松次序实现,具体原理可以参考接下来有关于宽松次序章节的内容。这里你只需要知道:虽然线程t1按次序执行1和2,但是因为宽松序列并不能保证线程间的同步性或先行性,所以线程t2看到的可能是y为true,x为false(可能先执行2→1,也可能先执行1→2)。进而导致TestOrderRelaxed可能会触发断言z为0。
但如果换成memory_order_seq_cst,则能保证所有线程看到的执行顺序是一致的。
1 | void write_x_then_y() { |
上面的代码x和y采用的是memory_order_seq_cst,所以当线程t2执行到3处并退出循环时我们可以断定y为true,因为是全局一致性顺序,所以线程t1已经执行完2处将y设置为true,那么线程t1也一定执行完1处代码并对t2可见,所以当t2执行至4处时x为true,那么会执行z++保证z不为零,所以一定不会触发断言(因为全局一致性顺序能保证线程间的先行性和同步性,所以如果线程t2可以退出循环,说明y中的值被修改为true,因为在线程t1中1顺序先行于2发生,而2必须先行于3发生,所以1也先行于3发生。那么当3执行成功后,其实1处对x的修改是对3可见的,因为在线程t2中,3又顺序先行行于4,那么x的值对4也是可见的,所以必定会++z)。
SC的缺点:
实现
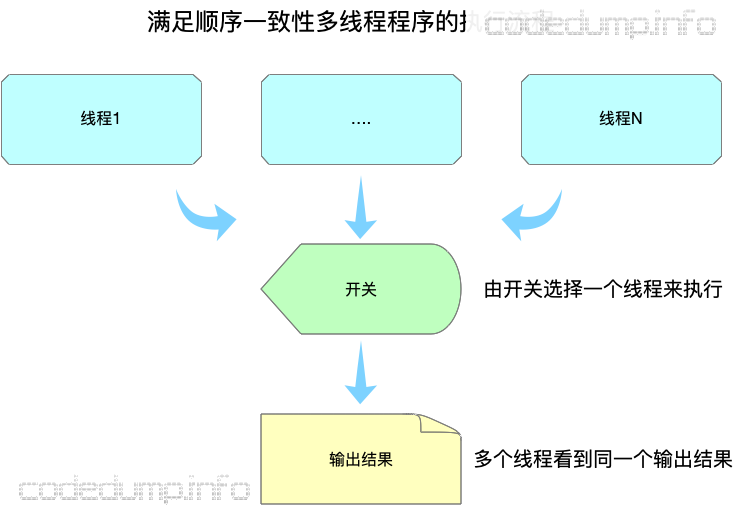
sequencial consistent模型有一定的开销,现代 CPU 通常有多核,每个核心还有自己的缓存。为了做到全局顺序一致,每次写入操作都必须同步给其他核心。为了减少性能开销,如果不需要全局顺序一致,我们应该考虑使用更加宽松的顺序模型。SC实际上是一种强一致性,可以想象成整个程序过程中由一个开关来选择执行的线程,这样才能同时保证顺序一致性的两个条件:

图片来源:https://www.codedump.info/post/20191214-cxx11-memory-model-1/#sequential-consistency-%E9%A1%BA%E5%BA%8F%E4%B8%80%E8%87%B4%E6%80%A7 可以看到,这样实际上还是相当于同一时间只有一个线程在工作,这种保证导致了程序是低效的,无法充分利用上多核的优点。
3. 宽松次序
- 宽松序列其实就是内存序
std::memory_order_relaxed,该操作要求原子性。 - 该内存序实现了内存模型
Relaxed ordering。 - 适用操作:读(
load)、写(store)、读改写(read-modify-write)。 - 适用场景:当同步关系或先行关系不是关键需求,而只需利用原子性来避免数据竞争的场景。
3.1 什么是 Relaxed ordering
std::memory_order_relaxed有以下几个功能:
作用于原子变量(利用操作不可分割的特性)。
原子类型上的操作不存在同步关系(synchronizes-with),即不会隐式地向其他线程传播可见性或顺序性信息。线程间仅存的共有信息是每个变量的改动序列。
1
2
3
4
5
6
7
8
9
10
11
12
13std::atomic<int> x{0};
std::atomic<int> y{0};
void thread1() {
x.store(1, std::memory_order_relaxed);
y.store(2, std::memory_order_relaxed);
}
void thread2() {
int a = y.load(std::memory_order_relaxed);
int b = x.load(std::memory_order_relaxed);
std::cout << a << " " << b << std::endl;
}在
thread2中,a和b的值可能会以任何顺序出现(包括a=2, b=0或a=0, b=1),因为操作之间没有同步关系。在单线程中,对同一个变量上的操作严格服从先行关系,但不同变量不具有先行关系,操作顺序可以重排,即可以乱序执行(因为 relaxed 模式不会对指令的全局顺序作任何保证,编译器会对代码进行优化和CPU 对指令重排)。
1
2
3
4
5
6
7
8
9
10
11int A, B;
void foo() {
A = B + 1;
B = 0;
}
int main() {
foo();
return 0;
}如果在不使用优化的情况下编译,gcc foo.c -S,foo函数中针对A和B操作的汇编代码如下:
1
2
3
4movl B(%rip), %eax
addl $1, %eax
movl %eax, A(%rip)
movl $0, B(%rip)即先把变量B的值赋给寄存器eax,将寄存器eax加一的结果赋值给变量A,最后再将变量B置为0。
而如果使用O2优化编译,代码重排,gcc foo.c -S -O2 则得到下面的汇编代码:
1
2
3
4movl B(%rip), %eax
movl $0, B(%rip)
addl $1, %eax
movl %eax, A(%rip)即先把变量B的值赋给寄存器eax,然后变量B置零,再将寄存器eax加一的结果赋值给变量A。
这个步骤就和代码中的执行顺序不符合。其原因在于,foo函数中,只要将变量B的值暂存下来,那么对变量B的赋值操作可以被打乱而并不影响程序的执行结果,这就是编译器可以做的重排序优化。
以微信群聊消息为例子说明这个问题。假设有多人在群里聊天,如果A说的消息1与B说的消息2之间,没用明确的先后顺序,比如消息1是回复或者引用了消息2的话,那么其实在整个群聊视图里面,两者的先后顺序如何是无关紧要的。即参与群聊的两个用户,其中一个用户可能看到消息1在消息2之前,另一个用户看到的顺序相反,这都是无关大局的,因为两个消息之间没有关系。
多线程下不存在先行关系(可见性),换句话说,
relaxed模式不保证某个线程对原子变量的写入对其他线程的读操作立即可见,可能得过一会儿后,其他 线程才能读到原子变量更新后的值。
综上,对该内存序的唯一要求是:在单线程内,对相同变量的访问次序不得重新编排,即在一个线程中,如果某个表达式已经看到原子变量某时刻持有的值a,则该表达式的后续表达式只能看到a或者比a更新的值。
我们可以通过两个线程说明,采用宽松次序的操作能宽松到什么程度,代码如下:
1 | std::atomic<bool> x, y; |
我们启动了两个线程t1和t2,分别调用 write_x_then_y() 和 read_y_then_x() ,前者将原子变量x和y的值通过原子操作store修改为true;后者通过判断x和y的值执行相关的操作。
- 在理想情况下,线程t1执行的任务会将原子变量x和y按顺序置为true,从而在线程t2执行的任务中,将z的值++,主函数断言成功,z确实不为0,程序不报错。
- 但是还有一种情况,2 处先于 1 处执行,那么此时在 t2 任务中, y为true跳出循环,但是x仍然为 false,z不++,导致断言失败,程序报错。
我们还可以从以下两个角度分析:
- 从cpu架构分析
假设线程 t1 运行在 核1上,t2 运行在 核3上,那么 t1 对x和y的操作,t2 是看不到的(如果t1没将数据写入至Memory中)。比如当线程t1运行至1处将x设置为true,t1运行至2处将y设置为true。这些操作仅在核1的store buffer中,还未放入cache和memory中,核3 自然不可见。
如果 核1 先将y放入memory,那么核3就会读取y的值为true。那么t2就会运行至3处从while循环退出,进而运行至4处,此时核1还未将x的值写入memory。t2读取的x值为false,进而线程t2运行结束,然后核1将x写入true, t1结束运行,最后主线程运行至5处,因为z为0,所以触发断言。
- 从宽松内存序分析
因为memory_order_relaxed是宽松的内存序列,它只保证操作的原子性,并不能保证多个变量之间的顺序性,也不能保证同一个变量在不同线程之间的可见顺序。
比如t1可能先运行2处代码再运行1处代码,因为我们的代码会被编排成指令执行,编译器在不破坏语义的情况下(2处和1处代码无耦合,可调整顺序),2可能先于1执行。如果这样,t2运行至3处退出while循环,继续运行4处,此时t1还未执行1初代码,则t2运行4处条件不成立不会对z做增加,t2结束。这样也会导致z为0引发断言。
还有一个涉及1个原子变量和4个线程的例子:
1 | void TestOderRelaxed2() { |
我们创建了一个类型为atomic<int>的变量a,两个vector容器v3和v4以及4个线程t1、t2、t3、t4。
线程t1向原子变量a中存储偶数,线程t2向a中存储奇数,线程t3从原子变量a中读取数据写入v3中,线程t4从原子变量a中读取数据写入v4中。这四个线程并发执行,最后打印v3和v4的数据。
运行代码
因为memory_order_relaxed不保证顺序性和可见性:
- 顺序性:
t1和t2写入的顺序未定义,可能会交错。 - 可见性延迟:
t3和t4读取的值不一定是最新的值(可能滞后)。
如果机器性能足够好,t1 和 t2 执行完所有写入操作时(最后一次是线程t2写入奇数9),t3 和 t4 才开始读取,那么 a 的最终值已经是 9,因此 t3 和 t4 的所有读取结果都会是 9。我们看到的可能是这种输出
1 | v3: 9 9 9 9 9 9 9 9 9 9 |
如果 t1 和 t2 与 t3 和 t4 并发执行,那么 t3 和 t4 在读取 a 的值时,可能捕捉到某些时刻的中间状态,导致 v3 和 v4 中的值看起来是乱序的。也可能是这种
1 | v3: 0 1 7 6 8 9 9 9 9 9 |
但我们能确定的是如果v3中7先于6,8,9等,那么v4中也是7先于6,8,9。
因为多个线程仅操作了a变量,通过memory_order_relaxed的方式仅能保证对a的操作是原子的(同一时刻仅有一个线程写a的值,但是可能多个线程读取a的值)。
但是多个线程之间操作不具备同步关系,自然也就构成不了先行关系,那么多个线程之间就不存在可见性。也就是线程t1将a改为7,那么线程t3不知道a改动的最新值为7,它读到a的值为1。只是要过一阵子可能会读到7或者a变为7之后又改动的其他值。
但是t3,t4两个线程读取a的次序是一致的,比如t3和t4都读取了7和9,t3读到7在9之前,那么t4也只能读取到7在9之前。因为我们memory_order_relaxed保证了多线程对同一个变量的原子操作的安全性,不同线程读取该原子变量的值,要么读到旧值要么读到新值,只不过新值可见性会有延迟。
1 | void TestOrderRelaxed() { |
上面的代码在一定程度上会触发断言4。因为线程 t1 执行完 1,2之后,有可能1 的操作先放入内存,也有可能2操作的结果先放入内存中被t2看到(memory_order_relaxed无先行关系,所以变量存入内存的顺序也不能保证顺序),此时t2执行退出3循环进而执行4,此时t2看到的rx值为false触发断言。
我们称2和3不构成同步关系, 2 “ not synchronizes with “ 3(因为2写入的值并不能保证被3立刻看到,虽然2被执行修改并放入了缓存stroebuffer,但是可能还没有放入Cache或者Memory中,导致其他核(线程)无法在第一时间看到)
如果能保证2的结果立即被3看到, 那么称 2 “synchronizes with “ 3(但在memory_order_relaxed中,不可能存在同步关系)。
如果 2 同步于 3还有一层意思就是,如果在线程t1 中 1 顺序先于 2(sequence before), 那么 1先行于3。那我们可以理解t2执行到3处时,可以获取到t1执行1操作的结果,也就是rx为true。t2线程中3顺序先于4(sequence before),那么1 操作自然也先行于 4。也就是1 操作的结果可以立即被4获取。进而不会触发断言(上述过程的推演都基于先行关系的延续性)。
宽松次序的缺点:
- 提供最小的内存序约束,仅保证操作的原子性,而不保证同步性或可见性。
4. 获取-释放次序(Acquire-Release)
- 获取-释放次序其实就是内存序
std::memory_order_consume、std::memory_order_acquire、std::memory_order_release、std::memory_order_acq_rel互相的排列组合。 - 这四种内存序实现了内存模型
Acquire-Release。 std::memory_order_consume在大多数情况下和std::memory_order_acquire相同。- 适用操作:
- 存储(
store)操作,可选用的内存次序有std::memory_order_relaxed、std::memory_order_release或std::memory_order_seq_cst。 - 载入(
load)操作,可选用的内存次序有std::memory_order_relaxed、std::memory_order_consume、std::memory_order_acquire或std::memory_order_seq_cst。 - “读-改-写”(
read-modify-write)操作,可选用的内存次序有std::memory_order_relaxed、std::memory_order_consume、std::memory_order_acquire、std::memory_order_release、std::memory_order_acq_rel或std::memory_order_seq_cst。
- 存储(
因为std::memory_order_consume、std::memory_order_acquire基本相同,总结下来其实内存模型 Acquire-Release是由std::memory_order_acquire、std::memory_order_release、std::memory_order_acq_rel实现的,它们的具体用法:
- 对原子变量的
load可以使用memory_order_acquire内存顺序,这称为acquire操作。 - 对原子变量的
store可以使用memory_order_release内存顺序,这称为release操作。 read-modify-write操作即读 (load) 又写 (store),它可以使用memory_order_acquire,memory_order_release和memory_order_acq_rel:- 如果使用
memory_order_acquire,则作为 acquire 操作; - 如果使用
memory_order_release,则作为 release 操作; - 如果使用
memory_order_acq_re,则同时为两者。
- 如果使用
4.1 什么是Acquire-Release
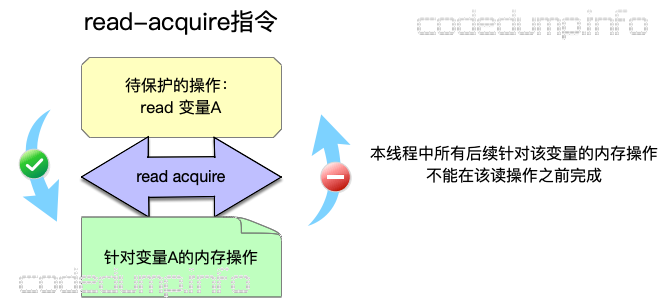
memory_order_acquire:用来修饰一个读操作,表示在本线程中,所有后续的关于此变量的内存操作都必须在本条原子操作完成后执行,也就是确保该读取操作之前的所有写操作不被重排到该操作之后,确保在此之前的所有写操作都在此写操作完成前对其他线程可见
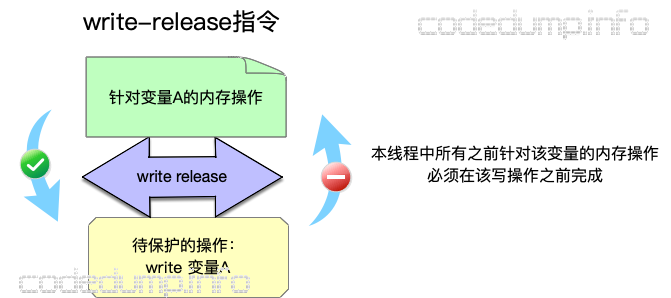
memory_order_release:用来修饰一个写操作,在当前线程中,memory_order_release之前的所有写操作(包括非原子操作)在释放时对其他线程可见,确保该写操作之后的所有读写操作不会被重排到该操作之前,确保在此之后的所有读操作只会在此读操作完成之后进行
memory_order_acq_rel:同时包含memory_order_acquire和memory_order_release标志。
简而言之就是,任何指令都不能重排到 acquire 操作的之后, 且不能重排到 release 操作的之前
acquire-release 可以实现 synchronizes-with(同步)关系。如果一个
acquire操作在同一个原子变量上读取到了一个release操作写入的值,则这个release操作 “synchronizes-with” 这个acquire操作。
我们以宽松次序中的一个例子举例:
1 | void TestOrderRelaxed() { |
在宽松次序中,上面所有的内存序均为std::memory_order_relaxed,导致 2 和 3 不构成同步关系, 2 “ not synchronizes with “ 3。而这里通过使用Acquire-Release模型,2 和 3 可构成同步关系,即 2 “ synchronizes with “ 3。
从C++语句层面来看:
我们将ry的读操作使用的内存序换为
memory_order_acquire,将ry的写操作使用的内存序换为memory_order_release;当线程t1执行至 2 处将ry设置为true,线程t2执行至 3 处时,因为使用了Acquire-Release模型,所以 1 先行于 4(线程t1中 1 顺序先于 2(sequence before), 而2又先行于3,那么 1先行于3。那我们可以理解t2执行到3处时,可以获取到t1执行1操作的结果,也就是rx为true。t2线程中3顺序先行于4(sequence before),那么1 操作自然也先行于 4。也就是1 操作的结果可以立即被4获取)。从CPU指令层面来看:
如果原子变量使用了
store原子操作,且该原子操作传入了内存序memory_order_release,若在该行指令上面还有其他store原子操作(或者其他非原子的写操作),不管其他操作的内存序是memory_order_relaxed、memory_order_seq_cst还是memory_order_release,CPU指令都必须按顺序执行(比如这里2处使用了memory_order_release,那么不管1处的内存序是什么,CPU指令都必须是按 1→2 的顺序执行,将指令依次写入内存)。所以,只要CPU读到了
memory_order_release操作,那么编译器就一定是将这行指令包括这行指令前面的指令按顺序写入内存,必定有顺序先行性。
Acquire-release 的开销比 sequencial consistent 小。
在 x86 架构下,memory_order_acquire 和 memory_order_release 的操作不会产生任何其他的指令, 只会影响编译器的优化:任何指令都不能重排到 acquire 操作的前面, 且不能重排到 release 操作的后面;否则会违反 acquire-release 的语义。因此很多需要实现 synchronizes-with 关系的场景都会使用 acquire-release。
4.2 Release-Sequences
还有一种场景:假如多个线程对同一个变量执行memory_order_release内存序操作,另一个线程对这个变量执行memory_order_acquire内存序操作,那么有且仅有一个线程的memory_order_release操作能与这个memory_order_acquire线程构成同步关系。
1 | void ReleasAcquireDanger2() { |
代码如上,我们启用线程t1和线程t2对原子变量yd执行内存序为memory_order_release的store原子操作;启用t3线程对原子变量yd执行内存序为memory_order_acquire的load原子操作。
而导致线程t3从循环中退出的方式有两种:第一种是t1线程将yd修改为1;第二种是t2线程将yd修改为2。如果是第一种方式,代码不会触发断言,如果是第二种方式,代码会触发断言,因为第二种方式没有修改xd的值。所以该段代码有触发断言的风险。
并不是只有在 acquire 操作读取到 release 操作写入的值时才能构成 synchronizes-with 关系。为了说这种情况,我们需要引入 release sequence 这个概念。
针对一个原子变量 M 的 release 操作 A 完成后,接下来 M 上可能还会有一连串的其他操作.。如果这一连串操作是由
- 同一线程上的写操作
- 任意线程上的
read-modify-write操作
这两种构成的,则称这一连串的操作为以 release 操作 A 为首的 release sequence。这里的写操作和 read-modify-write 操作可以使用任意内存次序。
如果一个 acquire 操作在同一个原子变量上读到了一个 release 操作写入的值,或者读到了以这个 release 操作为首的 release sequence 写入的值,那么这个 release 操作(如果是release sequence ,那么只有第一个release 才会和acquire 构成同步关系) “synchronizes-with” 这个 acquire 操作。
1 | void ReleaseSequence() { |
我们启动三个线程t1、t2、t3分别执行不同的任务:
- 线程t1负责给容器data添加一个新元素 ‘42’ ,并将原子变量flag置为1;
- 线程t2负责对flag执行读改写操作,仅当flag的值是1时,该线程才会将flag的值修改为2;
- 线程t3负责读取flag的值是否为2,并判断data容器中的元素是否为42。
如果想要线程 t3 能退出循环,首先flag要等于2,那么就要等线程 t2 将flag设置为2,而flag设置为2又要等到线程 t1 将flag设置为1。所以我们线程顺序必须为 2->3->4。
线程t1中操作2是release操作,以2为开始,其他线程(t2)的读改写或写(其他线程的写或读改写的内存序可以任意)在release操作之后,我们称之为release sequence, t3要读取release sequence写入的值,所以我们称线程t1的release操作 “synchronizes with “线程t3的 acquire 操作。
4.3 Release-Consume
从上面对Acquire-Release模型的分析可以知道,虽然可以使用这个模型做到两个线程之间某些操作的 synchronizes-with 关系,但是这个粒度有些过于大了。
在很多时候,线程间只想针对有依赖关系的操作进行同步,除此之外线程中的其他操作顺序如何无所谓。比如下面的代码中:
1 | b = *a; |
其中第二行代码的执行结果依赖于第一行代码的执行结果,且第一行代码顺序先行于第二行代码,此时称这两行代码之间的关系为“carry-a-dependency ”。C++中引入的memory_order_consume内存模型就针对这类代码间有明确的依赖关系的语句限制其先后顺序。
memory_order_consume的同步范围仅限于有明确数据依赖的变量,范围相比memory_order_acquire缩小了很多很多
memory_order_consume 可以用于 load 操作。使用 memory_order_consume 的 load 称为 consume 操作。 如果一个 consume 操作在同一个原子变量上读到了一个 release 操作写入的值,或以其为首的 release sequence 写入的值,则这个 release 操作 “dependency-ordered before” 这个 consume 操作。其实多线程的依赖关系和同步关系的概念很相近,理解成同步也可以。
示例如下:
1 | void ConsumeDependency() { |
t2执行到(4)处时,需要等到ptr非空才能退出循环,这就依赖t1执行完(3)操作。
- 因此(3) “dependency-ordered before” (4),根据前文我们介绍了dependency等同于synchronizes ,所以(3) “inter-thread happens-before”. (4)
- 因为(3)种的
memory_order_release保证(1) “sequenced before” (2),(2) “sequenced before” (3),则(1) “sequenced before” (3) (即使(2)是非原子操作,但是memory_order_release能保证(3)之前的指令必须按顺序执行),所以(1) “happens-before “ (4) - 又因为(4)和(5)有明显的依赖关系,所以相当于(4) “happens-before “ (5),则(1) “happens-before “ (5)。
综上,(5)处断言不可能触发。
- 但是,虽然
memory_order_release将data = 42视为完整的写操作,并将其效果发布到其他线程中,而且(2)顺序先行于(3)。但是因为消费者线程使用的是memory_order_consume内存序,而consume只保证数据依赖链上的变量同步,因此可能无法观察到data = 42的更新。所以即使(2)顺序先行于(3),而(3) “dependency-ordered before” (4),但因为data和ptr没有任何依赖关系,所以我们不能认为(2) “dependency-ordered before” (4),即我们不能认为(2) “happens-before ” (4). - 如果我们将消费者线程的内存序从
memory_order_consume修改为memory_order_acquire,那么就可以构成(2) “happens-before ” (4),而(4)顺序先行于(5)、(6),所以(2) “happens-before ” (6),此时断言6不会触发。
| 特性 | memory_order_consume |
memory_order_acquire |
|---|---|---|
| 同步范围 | 仅保证与加载的变量存在数据依赖的内存操作可见,粒度更小。 | 保证所有先行写入操作在加载变量之后对当前线程可见,粒度更大。 |
| 数据依赖 | 利用显式数据依赖进行优化,仅同步必要的数据路径。 | 无需显式数据依赖,对全局范围内的内存操作进行同步。 |
| 性能 | 更高效,减少了不必要的内存屏障和同步。 | 性能较低,可能引入更多的内存屏障和同步开销。 |
| 硬件支持 | 对硬件架构要求较高,依赖数据依赖链支持(部分平台不可靠)。 | 被所有主流硬件架构支持,行为一致性更强。 |
| 编译器实现 | 许多编译器(如 GCC 和 Clang)会退化为 memory_order_acquire,导致性能优势丧失。 |
编译器完全支持,无需额外处理。 |
| 使用场景 | 适合需要极致性能优化、明确数据依赖的场景(较少使用)。 | 通用同步场景,尤其适用于需保证完整同步的操作。 |
| 易用性 | 难以维护,需手动分析数据依赖,容易出错。 | 更直观易用,不需要关心数据依赖。 |
5. 单例模式
我们在网络编程(13)——单例模式 | 爱吃土豆的个人博客说详细说明了单例模板,并通过智能指针双重检测的方式实现了一个单例模板,但是该模板有一个风险,我们可以通过原子类型和内存序进行修改。
此外,在C++11开始,我们可以通过更加简便的方式实现单例模式,我这里将这三种方式分别总结如下:
5.1 通过std::call_once和std::once_flag实现
该方式实现的单例模式可以添加自定义的删除器。
1 |
|
这是我通过C++11新特性实现的AsioIOServicePool线程池单例模式,主要通过构造一个静态成员函数和一个静态成员变量实现:
1 | static std::shared_ptr<AsioIOServicePool> _instance; |
5.2 静态成员函数实现
第二种方法通过定义一个静态成员函数构造一个逻辑层的单例模式。
相比于5.1实现的单例模式,该方法实现的单例模式无法添加删除器。
我们只需要定义一个静态成员函数GetInstance(),在该函数中返回局部静态变量instance,instance是LogicSystem 的实例。该方法只能在C++11及以后的平台才可以使用,因为返回局部静态变量只有在C++11及以上是线程安全的。
1 |
|
函数实现:
1 | LogicSystem& LogicSystem::GetInstance() { |
5.3 智能指针双重检测实现
1 | template <typename T> |
该方式是通过智能指针对懒汉式单例模式的优化修改,但是该方法存在一定的风险:
1 | std::shared_ptr<SingleAuto> SingleAuto::single = nullptr; |
在该段代码下,虽然两次输出的地址都是同一个,但是我们的单例会存在安全隐患。1处和4处代码存在线程安全问题,因为在4处通过智能指针new一个对象再赋值给变量时会存在多个指令顺序:
第一种情况
1 | 1 为对象allocate一块内存空间 |
第二种情况
1 | 1 为对象allocate一块内存空间 |
如果是第二种情况,在4处还未构造对象就将地址返回赋值给single,而此时有线程运行至1处判断single不为空直接返回单例实例,如果该线程调用这个单例的成员函数就会崩溃(因为对象还未构造,只返回了为该对象开辟的地址)。
我们通过我们这节的知识修改该单例模板:
1 | //利用智能指针解决释放问题 |
这种方法实现的单例模板解决了线程安全的问题。
这三种方式均可用于实现单例模式,但如果不需要额外添加删除器之类的操作,我们用第二种方法即可。