十五、day15 在并发编程(1)— 并发编程(5)中,我们学习了关于线程管控的一些知识;在并发编程(6)— 并发编程(8)中,我们学习了关于async的一些知识;在并发编程(10)~并发编程(14)中,我们学习了关于原子、内存序的知识。
从本节开始,我们学习如何通过前五节的知识构建基于锁实现的线程安全队列、栈、链表和查找表等;并通过10~14节实现对应无锁版本的队列、栈、链表等。
我们在前面其实已经实现了一个基于锁的线程安全的队列和栈,但是有一些问题;而且实现了无锁和有锁版本的环形队列,环形队列的实现基于线程安全,无安全隐患。
因为栈和队列有一些相似之处,我们从栈开始学习如何基于锁实现线程安全,并尝试实现无隐患的线程安全的栈和队列。从有锁开始逐渐向无锁演变。
参考:
恋恋风辰官方博客
C++并发编程实战(第2版)
1. 线程安全的栈 1.1 存在隐患的栈容器 在文章并发编程(3)——锁(上) | 爱吃土豆的个人博客 中我们提到了如何保护共享数据(切勿将受保护数据的指针或引用传递到互斥量作用域之外
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 struct empty_stack : std::exception{ const char * what () const throw () }; template <typename T>class threadsafe_stack { private : std::stack<T> data; mutable std::mutex m; public : threadsafe_stack () {} threadsafe_stack (const threadsafe_stack& other) { std::lock_guard<std::mutex> lock (other.m) ; data = other.data; } threadsafe_stack& operator =(const threadsafe_stack&) = delete ; void push (T new_value) { std::lock_guard<std::mutex> lock (m) ; data.push (std::move (new_value)); } std::shared_ptr<T> pop () { std::lock_guard<std::mutex> lock (m) ; if (data.empty ()) throw empty_stack (); std::shared_ptr<T> const res (std::make_shared<T>(std::move(data.top())); data.pop(); return res; } void pop(T& value) { std::lock_guard<std::mutex> lock(m); if (data.empty()) throw empty_stack(); value = data.top(); data.pop(); } bool empty() const { std::lock_guard<std::mutex> lock(m); return data.empty(); } };
该栈容器解决了我们在并发编程(3)——锁(上) | 爱吃土豆的个人博客 文章中提到的两个问题:
如果我们启动两个线程同时push一个元素,假设线程t1先启动,t1判断栈不为空,然后睡眠1s;t2在t1睡眠的时候也判断栈不为空,然后休息1s;当t1醒来之后将栈内唯一的元素pop出,成功执行;当t2醒来之后栈内已经没有元素,但因为t2之前判断栈不为空所以t2也会pop元素,此时就会报错,因为栈内已经没有元素可以pop了。
解决方法 :定义一个空栈异常,当栈在pop的时候并不像之前直接将元素取出,而是先判断栈是否为空,如果栈为空但仍然调用了pop函数,那么就弹出empty_stack()异常。但如果这么做的话,就需要我们在外层调用pop的时候使用catch捕获异常,进行相应的处理。但异常一般来说适用于处理和 预判突发情况的,对于一个栈为空这种常见现象,仅需根据返回之后判断为空再做尝试或放弃出栈即可,没必要返回异常。
1 2 3 4 struct empty_stack : std::exception { const char* what() const throw(); };
当程序内存暴涨或者数据本身占据过大内存时,pop可能会造成数据丢失问题,具体内容可参考并发编程(3)——锁(上) | 爱吃土豆的个人博客
解决方法: 基于以下原理重载两个版本的pop函数:先用top() 获取栈顶元素,随后再用pop() 将元素移出栈容器(也就是先进行拷贝,后pop ,这样报错也就只能在pop前面复制的步骤发生),这样就保障了数据安全,即使我们无法安全地复制数据,数据仍然保留在栈中。
第一个版本 是带引用类型的参数(直接将元素传递给引用参数 ,引用参数已经在外界开辟好了内存空间,不存在内存不足的问题);
第二个版本 是将pop出的元素封装成智能指针类型(将元素top传入调用智能指针res的拷贝构造函数,即使因为内存过大报错,但元素仍在栈中),然后返回(return的时候也只是返回智能指针,智能指针占用的内存不大 ,我们在外层只需解引用return的智能指针,即可使用栈pop出的内容)。
我们在文章的一开始说过,虽然该栈容器解决了以上两个问题,可以在多线程并发下线程安全的运行,但是有一些隐患 :
尽管上面的例子在多线程并发调用中是线程安全的,但锁的排他性仅容许一次只有一个线程访问栈中的数据,这会让其他线程可能为了获取锁而陷入等待,从而浪费资源。
该栈容器没有提供任何 “等待/添加数据” 的操作,假如栈容器已经没有多余空间容纳其他数据,而其他线程又等着添加数据,那么此线程就必须反复调用 empty() 函数,或者调用 pop() 函数判断栈是否为空,这是极为浪费算力资源的事情。
1.2 优化后的栈容器 我们可以优化代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 template <typename T>class threadsafe_stack_waitable { private : std::stack<T> data; mutable std::mutex m; std::condition_variable cv; public : threadsafe_stack_waitable () {} threadsafe_stack_waitable (const threadsafe_stack_waitable& other) { std::lock_guard<std::mutex> lock (other.m) ; data = other.data; } threadsafe_stack_waitable& operator =(const threadsafe_stack_waitable&) = delete ; void push (T new_value) { std::lock_guard<std::mutex> lock (m) ; data.push (std::move (new_value)); cv.notify_one (); } std::shared_ptr<T> wait_and_pop () { std::unique_lock<std::mutex> lock (m) ; cv.wait (lock, [this ]() { if (data.empty ()) { return false ; } return true ; }); std::shared_ptr<T> const res ( std::make_shared<T>(std::move(data.top()))) data.pop (); return res; } void wait_and_pop (T& value) { std::unique_lock<std::mutex> lock (m) ; cv.wait (lock, [this ]() { if (data.empty ()) { return false ; } return true ; }); value = std::move (data.top ()); data.pop (); } bool empty () const { std::lock_guard<std::mutex> lock (m) ; return data.empty (); } bool try_pop (T& value) { std::lock_guard<std::mutex> lock (m) ; if (data.empty ()) { return false ; } value = std::move (data.top ()); data.pop (); return true ; } std::shared_ptr<T> try_pop () { std::lock_guard<std::mutex> lock (m) ; if (data.empty ()) { return std::shared_ptr <T>(); } std::shared_ptr<T> res (std::make_shared<T>(std::move(data.top()))) ; data.pop (); return res; } };
我们通过并发编程(5)——条件变量、线程安全队列 | 爱吃土豆的个人博客 提到的条件变量 优化代码。
像前面实现的栈容器一样,我们实现了两种pop函数(引用和智能指针),但是在本例中,每一种又分成了两类:try_pop版本和wait_and_pop版本
try_pop 保证线程不会阻塞等待,如果栈有数据那就返回数据,如果没有数据就直接返回false或者空指针(对应引用和智能指针的两个方式)wait_and_pop 保证线程处于阻塞等待,如果栈有数据会返回数据,如果没有就通过条件变量挂起,释放持有的锁,直至该线程被唤醒。通过条件变量可以避免线程循环判断拿取数据,从而浪费资源。
虽然我们通过条件变量避免多线程并发时算力资源的浪费,但是该方式会引发另一个问题 :
假设栈此时为空,线程A从队列中消费数据并调用 wait_and_pop 进入挂起状态(如果栈没数据,调用该函数的线程会被挂起,直至其生产线程push数据进去)。与此同时,另一个线程B向栈中放入数据并调用 push 操作,随后通过 notify_one 随机唤醒挂起中的一个线程(如果多个线程调用wait_and_pop,但栈没有数据时,这些线程都会进入挂起状态)以便消费队列中的数据。
假如线程A从 wait_and_pop 被唤醒,如果在执行过程中(比如第3或第5步)因为内存不足引发异常(我们在第三节说过,如果数据本身太大,那么我们在调用拷贝构造时可能会因为内存不足而引发异常),我们之前分析过,即便出现异常,也不会影响栈中的数据,因此栈的数据仍然是安全的。然而,线程A一旦发生异常,其他线程就无法继续从队列中消费数据,除非线程B再次执行 push 操作。因为我们使用的是 notify_one,每次只能唤醒一个线程,因此如果被唤醒的线程A发生了异常,导致它无法继续执行,那么就没有其他线程能够消费栈中的数据。
我们可以通过以下三个方案解决上述问题:
wait_and_pop 失败的线程修复后再次取数据wait_and_pop 时失败(例如因为内存不足),修复错误后让该线程再次尝试获取数据。
**将 notify_one 改为 notify_all**:notify_one 修改为 notify_all,可以确保所有等待的线程都能接收到通知并被唤醒。这样一来,多个线程都有机会继续执行,避免了单个线程失败后没有其他线程被唤醒的问题。然而,notify_all 会导致所有线程同时竞争资源,这可能导致性能问题和不必要的上下文切换,浪费资源。
使用智能指针存储栈数据 :如果内存不够,智能指针会返回一个空指针nullptr
我们这里使用第三种方式优化,一个无隐患且线程安全的的栈容器实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 template <typename T>class threadsafe_stack_waitable { private : std::stack<std::shared_ptr<T>> data; mutable std::mutex m; std::condition_variable cv; public : threadsafe_stack_waitable () {} threadsafe_stack_waitable (const threadsafe_stack_waitable& other) { std::lock_guard<std::mutex> lock (other.m) ; data = other.data; } threadsafe_stack_waitable& operator =(const threadsafe_stack_waitable&) = delete ; void push (std::shared_ptr<T> new_value) { std::lock_guard<std::mutex> lock (m) ; data.push (std::move (new_value)); cv.notify_one (); } std::shared_ptr<T> wait_and_pop () { std::unique_lock<std::mutex> lock (m) ; cv.wait (lock, [this ]() { return !data.empty (); }); std::shared_ptr<T> const res = data.top (); data.pop (); return res; } void wait_and_pop (T& value) { std::unique_lock<std::mutex> lock (m) ; cv.wait (lock, [this ](){ return !data.empty (); }); value = std::move (*data.top ()); data.pop (); } bool empty () const { std::lock_guard<std::mutex> lock (m) ; return data.empty (); } bool try_pop (T& value) { std::lock_guard<std::mutex> lock (m) ; if (data.empty ()) { return false ; } value = std::move (*data.top ()); data.pop (); return true ; } std::shared_ptr<T> try_pop () { std::lock_guard<std::mutex> lock (m) ; if (data.empty ()) { return nullptr ; } std::shared_ptr<T> res = data.top (); data.pop (); return res; } };
需要注意的是,实现返回智能指针的pop函数时,我们不需要将栈中的数据先构造一个智能指针后,然后提供给需要返回的智能指针;因为栈中存储的元素类型的智能指针,我们直接将数据返回即可。
1 2 3 4 std::shared_ptr<T> const res (std::make_shared<T>(std::move(data.top()))) ; std::shared_ptr<T> const res = data.top ();
2. 线程安全的队列 2.1 基于智能指针的线程安全的队列 我们在文章并发编程(5)——条件变量、线程安全队列 | 爱吃土豆的个人博客 中通过条件变量实现了一个线程安全的队列,但我们通过条件变量实现的生产-消费者队列同样有上面通过条件变量实现的栈容器的问题 :
假设栈此时为空,线程A从队列中消费数据并调用 wait_and_pop 进入挂起状态(如果栈没数据,调用该函数的线程会被挂起,直至其生产线程push数据进去)。与此同时,另一个线程B向栈中放入数据并调用 push 操作,随后通过 notify_one 随机唤醒挂起中的一个线程(如果多个线程调用wait_and_pop,但栈没有数据时,这些线程都会进入挂起状态)以便消费队列中的数据。
假如线程A从 wait_and_pop 被唤醒,如果在执行过程中(比如第3或第5步)因为内存不足引发异常(我们在第三节说过,如果数据本身太大,那么我们在调用拷贝构造时可能会因为内存不足而引发异常),我们之前分析过,即便出现异常,也不会影响栈中的数据,因此栈的数据仍然是安全的。然而,线程A一旦发生异常,其他线程就无法继续从队列中消费数据,除非线程B再次执行 push 操作。因为我们使用的是 notify_one,每次只能唤醒一个线程,因此如果被唤醒的线程A发生了异常,导致它无法继续执行,那么就没有其他线程能够消费栈中的数据。
我们之前通过条件变量实现的线程安全的队列代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <queue> #include <mutex> #include <condition_variable> template <typename T>class threadsafe_queue { private : mutable std::mutex mut; std::queue<T> data_queue; std::condition_variable data_cond; public : threadsafe_queue (){} threadsafe_queue (const threadsafe_queue& other) { std::lock_guard<std::mutex> lk (other.mut) ; data_queue = other.data_queue; } void push (T new_value) { std::lock_guard<std::mutex> lk (mut) ; data_queue.push (new_value); data_cond.notify_one (); } void wait_and_pop (T& value) { std::unique_lock<std::mutex> lk (mut) ; data_cond.wait (lk, [this ] {return !data_queue.empty (); }); value = data_queue.front (); data_queue.pop (); } std::shared_ptr<T> wait_and_pop () { std::unique_lock<std::mutex> lk (mut) ; data_cond.wait (lk, [this ] {return !data_queue.empty (); }); std::shared_ptr<T> res (std::make_shared<T>(data_queue.front())) ; data_queue.pop (); return res; } bool try_pop (T& value) { std::lock_guard<std::mutex> lk (mut) ; if (data_queue.empty ()) return false ; value = data_queue.front (); data_queue.pop (); return true ; } std::shared_ptr<T> try_pop () { std::lock_guard<std::mutex> lk (mut) ; if (data_queue.empty ()) return std::shared_ptr <T>(); std::shared_ptr<T> res (std::make_shared<T>(data_queue.front())) ; data_queue.pop (); return res; } bool empty () const { std::lock_guard<std::mutex> lk (mut) ; return data_queue.empty (); } };
选择将队列元素类型定义为智能指针,从而避免拷贝时内存不足引发的异常问题(智能指针在赋值过程中会进行内存管理,但不会像普通指针那样引发异常,如果内存不够,智能指针会返回一个空指针nullptr),优化后的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 template <typename T>class threadsafe_queue_ptr { private : mutable std::mutex mut; std::queue<std::shared_ptr<T>> data_queue; std::condition_variable data_cond; public : threadsafe_queue_ptr (){} threadsafe_queue_ptr (const threadsafe_queue_ptr& other) { std::lock_guard<std::mutex> lk (other.mut) ; data_queue = other.data_queue; } void wait_and_pop (T& value) { std::unique_lock<std::mutex> lk (mut) ; data_cond.wait (lk, [this ] {return !data_queue.empty (); }); value = std::move (*data_queue.front ()); data_queue.pop (); } bool try_pop (T& value) { std::lock_guard<std::mutex> lk (mut) ; if (data_queue.empty ()) return false ; value = std::move (*data_queue.front ()); data_queue.pop (); return true ; } std::shared_ptr<T> wait_and_pop () { std::unique_lock<std::mutex> lk (mut) ; data_cond.wait (lk, [this ] {return !data_queue.empty (); }); std::shared_ptr<T> res = data_queue.front (); data_queue.pop (); return res; } std::shared_ptr<T> try_pop () { std::lock_guard<std::mutex> lk (mut) ; if (data_queue.empty ()) return std::shared_ptr <T>(); std::shared_ptr<T> res = data_queue.front (); data_queue.pop (); return res; } void push (T new_value) { std::shared_ptr<T> data ( std::make_shared<T>(std::move(new_value))) std::lock_guard<std::mutex> lk (mut) ; data_queue.push (data); data_cond.notify_one (); } bool empty () const { std::lock_guard<std::mutex> lk (mut) ; return data_queue.empty (); } };
其实和优化前的版本主要区别在元素类型上,优化前队列的元素类型是 T ,优化后队列的元素类型是智能指针。我们选择智能指针是为了避免普通指针因为内存分配而引发的异常,所以我们还需要对优化前的代码中关于内存分配的部分进行修改:
push 数据时需要先构造指针智能,然后将构造的指针指针压入队列中,这样可以避免先前代码可能会因为内存不足而引发异常,从而污染队列中的数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void push (T new_value) std::lock_guard<std::mutex> lk (mut) ; data_queue.push (new_value); data_cond.notify_one (); } void push (T new_value) std::shared_ptr<T> data (std::make_shared<T>(std::move(new_value))) ; std::lock_guard<std::mutex> lk (mut) ; data_queue.push (data); data_cond.notify_one (); }
智能指针仅 在调用构造函数时可能会因为内存不足而导致失败(但不会导致异常,智能指针会返回一个空指针nullptr),而智能指针间的赋值并不会引发异常,因为智能指针间的赋值不涉及内存的分配。
赋值操作不导致内存分配是因为智能指针的赋值通常是将一个已经分配的资源所有权转移或引用计数更新,而不是重新分配内存。例如,当你将一个智能指针赋值给另一个智能指针时,智能指针会复制原指针的资源管理权或增加引用计数,而不是重新分配内存或创建新的资源。因此,内存分配只在构造新的智能指针或创建新的资源时发生,而赋值操作只是管理已存在的资源。
使用智能指针存储数据不仅能防止内存不够抛出异常,而且能够有效节省资源,智能指针间的赋值不涉及内存的分配(但是创建一个指针会占8字节)
其实创建一个智能指针共享资源也会造成一定程度的内存开销,只不过很少,因为智能指针在栈上开辟,占8字节,所以每创建一个新的智能指针,便会在栈上开辟8字节的空间。
通过智能指针实现的队列已经能够满足我们的大部分工作,但是如果我们想要多线程并发使用队列时,不可避免的需要考虑到效率问题,那么该代码因为push 和 pop 函数施加同步是用的同一个 mutex,这会导致 push 和 pop 在多线程环境中串行化 ,从而效率会大幅度降低。而且因为线程的上下文切换也会造成一定的损耗,在后文中,我们学习如何通过内存模型和原子操作实现无锁队列 。
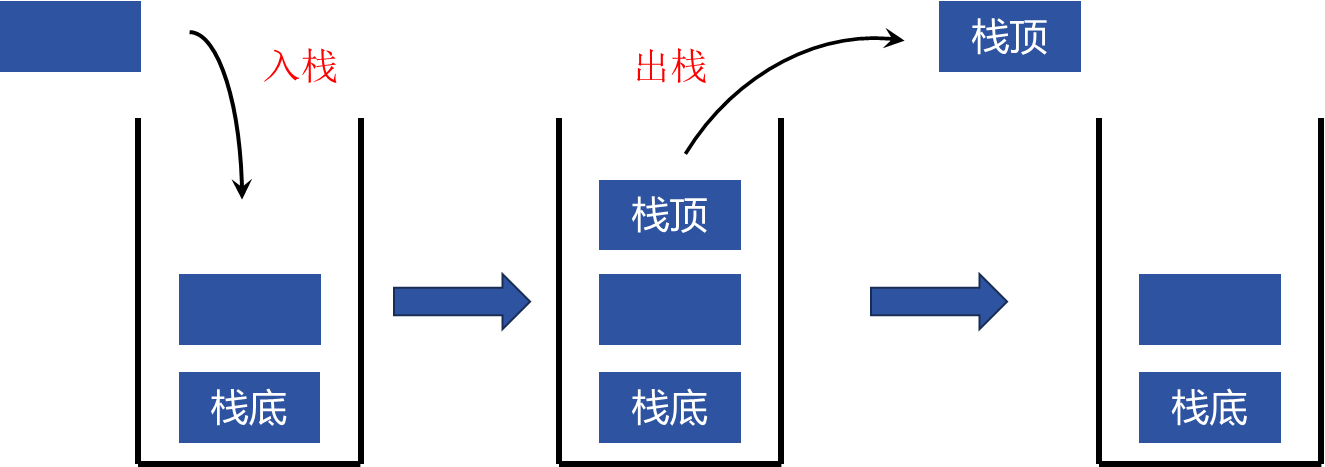
2.2 不同互斥量管理队首、队尾的队列 队列和栈最大的区别就是:栈是先入后出的,队列是先入先出的,如下图
栈:先入后出
队列:先入先出
在上面的代码中,push 和 pop 函数施加同步是用的同一个 mutex,这会导致 push 和 pop 在多线程环境中串行化 ,即,一个线程执行 push ,那么其他线程就没办法执行 pop 或 push,虽然我们通过条件变量挂起了这些线程,避免了算力资源的浪费,但是我们没有办法实现 push 和 pop 的同时调用。
在库中,队列一般是通过双向链表实现的,首节点和尾节点分别进行出队和入队操作,我们可以考虑对队首和队尾分别使用不同的互斥量进行管理,实现真正的并发,而不是在同一时刻有且仅有一个线程实现一个操作。
要想自己实现一个基于链表的队列,需满足以下操作:
定义一个虚拟头节点,没有任何数据,队列为空 时头节点和尾节点均指向虚拟头节点。
执行 push 操作时,将尾指针指向的节点的 next 指针指向新加入的节点,并更新尾指针使其指向新节点。
执行 pop 操作时,先检查队列是否为空,在满足条件的情况下,更新头指针使其指向下一个节点。
这部分是链表的内容,我就不详细说明了,可以在力扣上完成这道题:707. 设计链表 - 力扣(LeetCode) 熟悉链表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 template <typename T>class threadsafe_queue_ht { private : struct node { std::shared_ptr<T> data; std::unique_ptr<node> next; }; std::mutex head_mutex; std::unique_ptr<node> head; std::mutex tail_mutex; node* tail; std::condition_variable data_cond; node* get_tail () { std::lock_guard<std::mutex> tail_lock (tail_mutex) ; return tail; } std::unique_ptr<node> pop_head () { std::unique_ptr<node> old_head = std::move (head); head = std::move (old_head->next); return old_head; } std::unique_lock<std::mutex> wait_for_data () { std::unique_lock<std::mutex> head_lock (head_mutex) ; data_cond.wait (head_lock,[&] {return head.get () != get_tail (); }); return std::move (head_lock); } std::unique_ptr<node> wait_pop_head () { std::unique_lock<std::mutex> head_lock (wait_for_data()) ; return pop_head (); } std::unique_ptr<node> wait_pop_head (T& value) { std::unique_lock<std::mutex> head_lock (wait_for_data()) ; value = std::move (*head->data); return pop_head (); } std::unique_ptr<node> try_pop_head () { std::lock_guard<std::mutex> head_lock (head_mutex) ; if (head.get () == get_tail ()) { return std::unique_ptr <node>(); } return pop_head (); } std::unique_ptr<node> try_pop_head (T& value) { std::lock_guard<std::mutex> head_lock (head_mutex) ; if (head.get () == get_tail ()) { return std::unique_ptr <node>(); } value = std::move (*head->data); return pop_head (); } public : threadsafe_queue_ht () : head (new node), tail (head.get ()){} threadsafe_queue_ht (const threadsafe_queue_ht& other) = delete ; threadsafe_queue_ht& operator =(const threadsafe_queue_ht& other) = delete ; std::shared_ptr<T> wait_and_pop () { std::unique_ptr<node> const old_head = wait_pop_head (); return old_head->data; } void wait_and_pop (T& value) { std::unique_ptr<node> const old_head = wait_pop_head (value); } std::shared_ptr<T> try_pop () { std::unique_ptr<node> old_head = try_pop_head (); return old_head ? old_head->data : std::shared_ptr <T>(); } bool try_pop (T& value) { std::unique_ptr<node> const old_head = try_pop_head (value); return old_head; } bool empty () { std::lock_guard<std::mutex> head_lock (head_mutex) ; return (head.get () == get_tail ()); } void push (T new_value) { std::shared_ptr<T> new_data ( std::make_shared<T>(std::move(new_value))) std::unique_ptr<node> p (new node) ; node* const new_tail = p.get (); std::lock_guard<std::mutex> tail_lock (tail_mutex) ; tail->data = new_data; tail->next = std::move (p); tail = new_tail; data_cond.notify_one (); } };
节点我们通过C++的方式实现:数据使用 shared_ptr 构造,可以避免一些异常错误,next 指针通过 unique_ptr实现,std::unique_ptr<node>和node*的效果一样。
1 2 3 4 5 struct node { std::shared_ptr<T> data; std::unique_ptr<node> next; };
此外,head 指针使用了 std::unique_ptr<node> 进行构造,tail 指针使用了 node*,所以构造函数 1 中的操作是正确的:
1 threadsafe_queue_ht () : head (new node), tail (head.get ()){}
我们可以使用指针指针通过 get 函数获取的原始指针构造普通指针,但不能构造其他智能指针,否则会导致所有权转移或者引用计数独立的问题。比如使用head的原始指针构造另一个unique_ptr,那么head的所有权会被转移给构造的unique_ptr。如果构造的是另一个shared_ptr,并且head也是shared_ptr,那么两个shared_ptr不共享引用计数,二者是独立的。
在 push 函数中,流程如下:
先构造一个T类型的智能指针存储push的数据new_data;
然后构造一个新的节点 p;
获取p的裸指针new_tail,用于更新队列的尾部,p此时仍然管理这个裸指针new_tail;
将新的数据存入当前尾指针指向的节点,然后将新节点 p 的所有权转移给当前尾指针的 next 指针;
最后将尾指针更新为新的尾部new_tail。这里 new_tail 是指向新创建节点的裸指针,而 p 现在是空的,因为它的所有权已被转移。(新的尾指针data和next均为空)
数据使用 std::shared_ptr 构造,next 指针使用 std::unique_ptr 构造
3,4处都是wait_and_pop的不同版本,内部调用了wait_pop_head,wait_pop_head内部先调用wait_for_data判断队列是否为空,这里判断是否为空主要是判断head是否指向虚位节点。如果不为空则返回unique_lock,我们显示的调用了move操作,返回unique_lock仍保留对互斥量的锁住状态。最后调用pop_head将头数据pop出来。
值得注意的是get_tail()返回tail节点,tail 可能在不同的线程中被更新,导致 get_tail() 获取的尾节点并不是最终的尾节点。我们此时在5处的判断可能是基于push之前的tail信息,但是不影响逻辑,因为如果head和tail相等则线程挂起,等待通知,如果不等则继续执行,push操作只会将tail向后移动不会导致逻辑问题。