
十六、day16
在上一节,我们学习了关于队列和栈的相关知识,但它们都只是简单的容器,接口极度受限,而且严格针对特定用途。但并非所有数据结构都如此简单,比如今天学习的查找表。
参考:
Java-链表(单向链表、双向链表) - 南孚先生 - 博客园
1. 如何实现查找表
查找表(又称字典)相当于map,可以根据给定的 “键 ”查找对应的 “值” ,分为两类:
- 查找符合条件的数据元素
- 插入、删除某个数据元素
满足条件 1 的是静态查找表,满足条件 1 和 2 的是动态查找表。
查找表一共有三种查找方式:
- 顺序查找(从头到尾依次查找)
- 折半查找(二分法)
- 分块查找(首先在索引表内确定待查记录所属的分块,然后在块内顺序查找)
在上一节中,我们提到了队列容器中,push 和 pop 函数施加同步是用的同一个mutex,这会导致 push 和 pop 在多线程环境中串行化。所以我们需要考虑精细粒度锁操作,而不是将一个现成的容器包装起来使用(上一节中,我们实现了链表方式存储的队列),所以我们不能直接使用现成的容器,比如std::map<>、std::muotimap<>、std::unordered_map<>、std::unordered_multimap<>,而是需要自己定义一个数据结构实现查找表。
但上面的四种现有map容器的实现方式多样,比如std::map<>既可以用红黑树实现,也可以用有序数组实现,而std::unordered_map通过哈希表实现,我们究竟使用哪一种方式实现我们自定义的查找表呢?
| 容器类型 | 实现方式 | 是否有序 | 是否允许重复键 | 时间复杂度(查找/插入/删除) | 遍历特性 |
|---|---|---|---|---|---|
std::map |
红黑树/有序数组 | 是 | 否 | O(logn)O(\log n)O(logn) | 支持键值顺序遍历 |
std::multimap |
红黑树/有序数组 | 是 | 是 | O(logn)O(\log n)O(logn) | 支持键值顺序遍历 |
std::unordered_map |
哈希表 | 否 | 否 | 平均 O(1)O(1)O(1),最坏 O(n)O(n)O(n) | 无序,按哈希顺序 |
std::unordered_multimap |
哈希表 | 否 | 是 | 平均 O(1)O(1)O(1),最坏 O(n)O(n)O(n) | 无序,按哈希顺序 |
但是吧,红黑树在并发面前的可操作性非常低,因为红黑树每次查找或改动都要从根节点开始访问,因而必须对其加锁。访问线程线程会逐层向下移动,根节点上的锁会随之释放,每次访问都需要对根节点进行加锁、解锁,然后频繁的使用重平衡操作查找对应的节点进行修改,存在一定的开销。但相比整个数据结构单独使用一个锁,仍然要好上不少。
而有序数组在并发环境中需要对整个数据结构单独使用一个锁,因为查找目标时无法提前确定具体的位置。由于我们无法像树那样逐层访问来加锁释放,只能一次性锁住整个数组,确保操作时不会发生数据冲突。
哈希表相比上面两种方式无疑是更好的选择,哈希表有很多个桶(哈希函数生成的值,我们这里用链表的方式存储桶中值),每个关键字(key)都属于一个桶,因为每个桶都占据一块独立的内存,所以我们可以为每个桶单独的施加独立的锁。如果采用读写锁(共享锁),支持多个读线程和一个写线程,就会令并发操作的操作性增加N倍,N是桶的数目。
唯一短处是我们需要自定义一个哈希函数,当然也可以使用C++标准库提供的函数模板std::hash<>。哈希表的索引(桶的索引)其实是根据一个复杂函数(哈希函数)得出的,比如存在以下哈希函数:
$$
H(key)=key % 13
$$
存在一堆数据元素:
$$
key = {19, 14, 23, 1, 68, 20, 84, 27, 55, 11, 10, 79}
$$
我们将通过哈希函数生成的值作为桶的索引存放至连续的vector容器中,我们会得到以下数据结构:
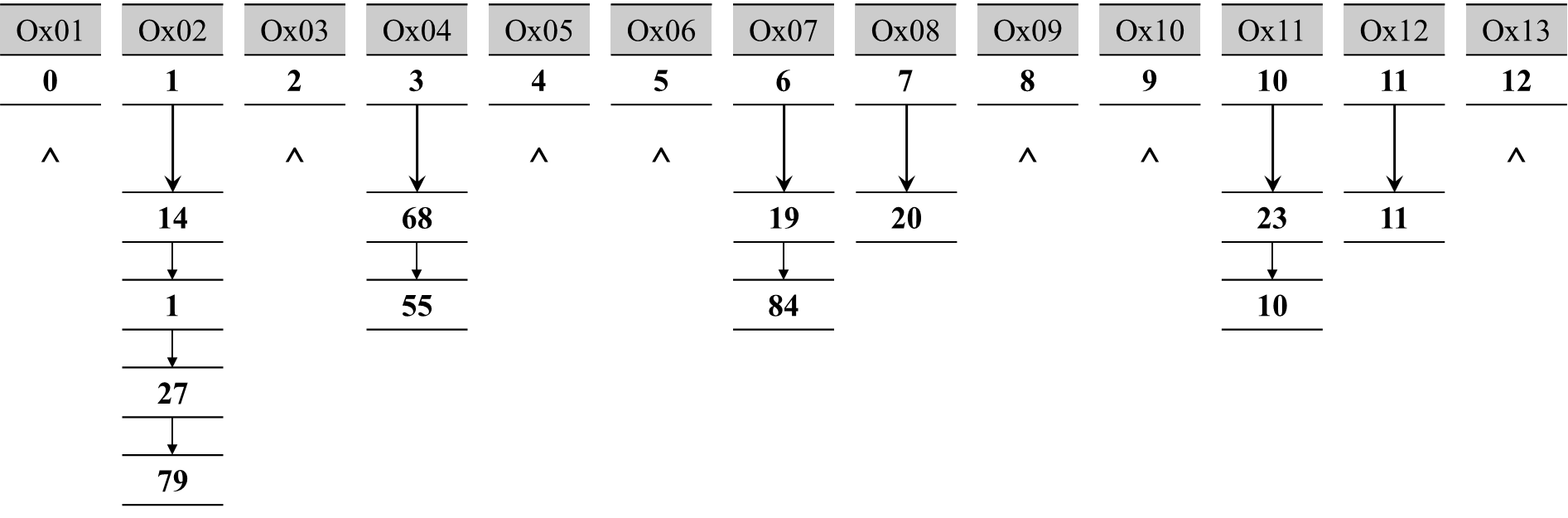
从上表我们可以看出来:
- 不同的关键字(key)通过哈希函数映射到同一个值,这个关键字称为 “同义词”
- 通过哈希函数确定的位置如果已经存放了其他元素,我们称其为 “冲突”,一般使用 ”拉链法“ 解决,即把所有 “同义词” 存储至一个链表中。在上面,我们将映射至为 1 的 “同义词” 存通过一个链表存储起来,14->1->27->79
解决 ” 冲突“ 的方法除 ”拉链法“ 外,还有”开放定址法“:指可存放新表项的空闲地址既向它的同义词表项开放,又向它的非同义词表项开放。这里不多过叙述,可以自行查找相关的资源。
2. 如何设计?
首先将19, 14, 23, 1, 68, 20, 84, 27, 55, 11, 10, 79等键对应的 hash值 放入一个vector中,多线程根据key计算得出hash值的过程不需要加锁,可以实现并行计算。但是对于链表的增删改查需要加锁(这里对链表的修改只使用一个锁,并发性比较差,但在本节中不对其进行优化,具体优化过程可以参考下一节关于基于同步方式实现线程安全的链表)。我们将链表封装为一个类bucket_type,支持数据的增删改查。
我们将整体的查找表封装为threadsafe_lookup_table类,实现哈希规则和调度桶类bucket_type。
使用上面使用的查找表例子来作解释:
比如存在以下哈希函数:
$$
H(key)=key % 13
$$
存在一堆数据元素:
$$
key = {19, 14, 23, 1, 68, 20, 84, 27, 55, 11, 10, 79}
$$
假如键值对中所有键和值相同,即 Key = Value。
首先,键 19 经过哈希函数后得出 19 % 13 = 6,13是桶的数量,6是桶的索引。我们将键值对 19:19 存放至索引为 6 的桶中,后续桶索引为 6 的键值对通过链表的方式连接到上一个节点,比如键值对 84:84 连接至键值对 19:19 后面 。
剩下的几个键依次这样处理,最后得到如下图:
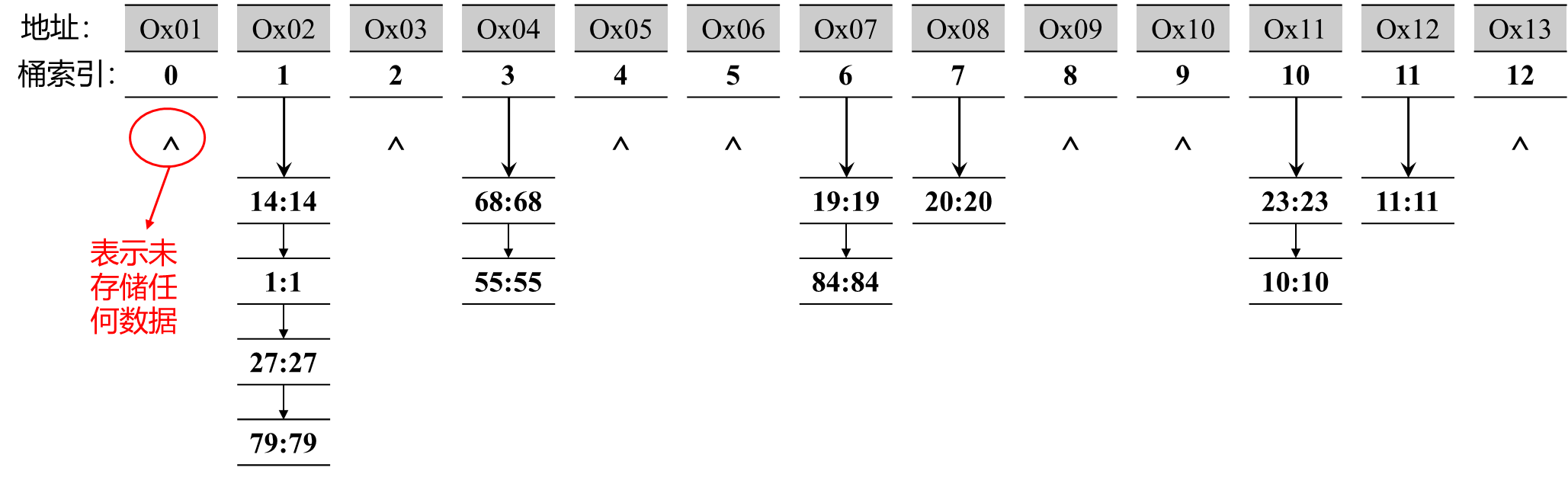
3. 线程安全的查找表
1 |
|
模板类threadsafe_lookup_table的模板类型Key、Value、Hash分别是键、值和哈希函数
1 | template<typename Key, typename Value, typename Hash = std::hash<Key>> |
然后定义了一个线程安全的桶类 bucket_type,用于实现哈希表中每个桶的存储和操作逻,每个桶负责存储一定范围的键值对。
3.1 bucket_type
该类用于实现哈希表中每个桶的存储和操作逻,每个桶负责存储一定范围的键值对。每个桶是一个链表(std::list),其中存储多个键值对
- 桶类的存储结构和类型定义如下
1 | //存储元素的类型为pair,由key和value构成 |
bucket_value:表示一个键值对,键为Key,值为Valuebucket_data:使用标准库的std::list存储键值对的容器,但因为我们采用的是标准库提供的list容器,所以增删改查等操作加的是同一把锁,导致锁过于粗糙,在下一节中我们需要对链表进行优化,对锁粒度进行改良bucket_iterator:std::list的迭代器,指向std::pair<Key, Value>,用于遍历或定位元素
在定义类型别名的时候需要注意,如果定义别名的类型是已知类型,直接加 typedef 即可,但对于模板类中嵌套的类型,我们需要额外加
typename明确是类型。
比如上面 std::pair 和 std::list 是标准库中的普通模板类,它们本身是已知类型,不需要额外的提示来区分;而bucket_data::iterator 是一个嵌套类型,定义在 bucket_data(即 std::list<bucket_value>)内部,我们需要加 typename 表明它是一个类型,而不是其他可能的非类型成员(数据成员、成员函数、静态成员变量、枚举值)
注意区分类型成员和非类型成员:
- 类型成员是类中定义的类型,主要包括:
typedef或using定义的类型别名、嵌套类、模板嵌套类型 - 非类型成员是类的对象或行为,而不是类型定义,主要包括:数据成员(成员变量)、成员函数、静态成员变量、枚举值
1 | class Example { |
为什么需要这样区分?
在模板中,C++ 编译器无法直接区分某个嵌套标识符是 非类型成员 还是 类型成员,因为模板参数可能影响其定义。例如:
1 | template <typename T> |
如果不加 typename,编译器可能认为 T::NestedType 是一个变量或其他非类型成员,而报错。但 T::static_member 是一个非类型成员(静态变量),因此不需要 typename。
- 桶类的私有成员变量定义如下:
1 | bucket_data data; |
data:存储桶中的所有键值对mutex:std::shared_mutex提供读写锁机制,使用mutable确保即使在 const 成员函数中仍可被修改。
- 私有成员函数:
1 | bucket_iterator find_entry_for(const Key& key) |
- 该函数用于遍历data,查找第一个键等于key的元素,如果找到,返回指向该元素的迭代器;否则返回
data.end()。 std::find_if是标准库中一个用于查找给定范围内第一个满足给定条件的元素的算法,否则返回超尾,这里不作介绍,只解释用于条件的lambda函数。- 该lambda函数引用捕获了容器中的元素(类型为bucket_value),并将形参的类型定义为 const bucket_value& 确保不会修改容器的元素值;
item.first == key确保元素的键等于给定的 key,如果等于则返回当前元素对应的迭代器,否则迭代下一个元素。
- 公有成员函数:
1 | Value value_for(const Key& key, const Value& default_value) |
- 该函数用于在data中查找键位 key 的值,找到返回键对应的 value,否则返回default_value
find_entry_for(key)函数上面介绍过了,返回指向持有给定键的元素的迭代器- 使用
std::shared_lock共享锁锁定共享互斥量shared_mutex确保多个线程可以同时查找
1 | void add_or_update_mapping(Key const& key, Value const& value) |
- 该函数用于向data中添加新的键值对,或更新已有键对应的值
- 使用独占锁锁定共享互斥
shared_mutex防止其他线程同时修改 - 实现:
- 首先查找持有给定 key 的元素的迭代器
- 然后判断该迭代器是否是超尾,如果是那么data中没有该键,将新键值对插入到data尾部;否则,更新对应 key 的值
1 | void remove_mapping(Key const& key) |
- 该函数用于从 data 中删除键位 key 对应的键值对
- 只要是修改,必须使用独占锁保护共享资源
- 实现:
- 首先查找持有给定 key 的元素的迭代器
- 然后判断该迭代器是否是超尾,如果不是那么data中存在键为key的键值对,直接删除
3.2 threadsafe_lookup_table
该类定义了一个线程安全的查找表,使用上面定义的桶类bucket_type来对键值对进行增删改查,std::vector存储多个桶,每个桶是一个链表(bucket_type),下面是具体的解释说明:
- 私有成员变量:
1 | class bucket_type{} |
- 嵌套类bucket_type已经在上面解释过了,用于键值对的增删改查
buckets:每个元素是一个独占指针(std::unique_ptr)指向桶(bucket_type)。每个桶用于存储多个键值对,桶的个数由哈希表构造函数指定。hasher:哈希函数,使用std::hash<Key>来计算键的哈希值
- 私有成员函数:
1 | bucket_type& get_bucket(Key const& key) const |
- 该函数通过给定的key计算哈希值,并根据哈希值对桶的数量取余来确定目标桶的索引
- 实现:
hasher(key):通过哈希函数计算key的哈希值% buckets.size():将哈希值映射到桶的索引范围- 通过索引返回对应的桶引用
- 构造函数:
1 | threadsafe_lookup_table(unsigned num_buckets = 19, const Hash& hasher_ = Hash()) : |
- 主要就是指定桶的数量以及哈希函数,桶的数量默认是19,哈希函数默认使用C++标准库的std::hash<Key>
- 最后为buckets数组容器中的每一个智能指针对象绑定一个 bucket_type 实例,并调用智能指针的reset()方法,将智能指针原本的指向对象消除,并指向new的bucket_type 实例
- 这里将复制构造函数和赋值运算符delete,禁止拷贝和赋值。因为我们定义了拷贝构造和赋值运算符(即使delete),移动构造和移动拷贝仍会被阻止隐式定义,我们无需关注它们
- 其他公有成员函数:
1 | Value value_for(Key const& key, const Value& default_value = Value()) |
- 该函数用于查找并返回指定 key 对应的 value,如果未找到则返回默认default_value
get_bucket(key)用于根据给定key查找对应索引的桶,并调用桶的成员函数value_for,返回给定 key 的 value- 桶的成员函数
value_for和threadsafe_lookup_table的value_for不同,后者是调用前者的
1 | void add_or_update_mapping(Key const& key, Value const& value) |
- 该函数用于添加新的键值对,若该键已存在,则更新键的值
- 其实就是先通过哈希函数获取对应目标桶的索引,然后调用该桶的成员函数进行键值对的添加或更新
1 | void remove_mapping(Key const& key) |
- 该函数用于删除指定 key 对应的键值对
1 | std::map<Key, Value> get_map() |
- 该函数返回一个包含所有键值对的查找表
std::map - 依次获取每个桶的共享互斥量
shared_mutex,并使用独占锁unique_lock锁定 - 依次获取每个桶中指向 data 的第一个 pair 元素的迭代器,然后迭代每个桶中的数据并插入至 map 对象,直至超尾
3.3 测试
在查找表中,我们可以根据给定的键查找对应的数据,这些数据的类型我们可以自定义也可以使用C++默认类型,我们这里选择自定义一个类用于存储数据:
1 | class MyClass |
该类使用私有成员变量 _data 存储整型数据,并重载了 << 符号用于输出该数据,这里必须将重载函数设为友元函数,因为是 std::ostream 类调用 MyClass 类的重载 << 符号。
测试函数如下:
1 | void TestThreadSafeHash() { |
初始化我们定义的查找表模板类,模板类型 Key 为int,Value 为指向自定义类 MyClass 的智能指针,并调用构造函数(桶数量默认为19,哈希函数默认使用系统提供的哈希函数)
1 | // 模板参数 |
首先创建三个线程 t1、t2、t3:
- t1 线程循环调用查找表的 add_or_update_mapping 函数,向查找表添加键值对(键值对的大小相同,都是for循环的次数),首先根据键(for循环的次数i)获得桶的索引,然后向目标桶内添加键值对
- t2 线程用于查找给定键(for循环的次数)的 value,如果没发现,返回 nullptr;如果给定键存在 value,那么删除查找表的该键值对,然后在定义的set类型的容器 removeSet 中插入该键,表示已被删除的键
- t3 线程和 t1 线程的功能一样,只不过线程 t1 的键从0
99,线程 t3 的键从100199
三个线程执行完之后,removeSet 应该保留了已删除的键099,而查找表中的键从099已被删除,只保留了100~199的键值对
最后把已删除的键从 removeSet 中依次打印出来,并把查找表目前的所有键值对的 value 依次打印出来
输出结果为:
1 | remove data is 0 |
3.4 缺陷
通过C++标准库提供的链表 list 存储键值对虽然对并发读不影响(共享锁保证多个线程可以线程安全的读共享数据),但是不能并发写,在同一时间有且仅有一个线程可以修改共享数据(因为C++标准库提供的链表的增删改查是通过同一个互斥量实现的,锁粒度不够精细),我们需要像上一节实现队列一样,自定义一个链表结构,通过多个锁来为增删查改进行保护,每个操作有自己独立的锁,实现写操作的并发。
下一节实现锁粒度精细的线程安全的链表。
这节实现的查找表线程安全,我们只需将桶类 bucket_type 使用的C++标准库提供的存储结构链表 list 替换为下一节实现的链表即可。