
十八、day18
在学习过如何通过互斥来实现高并发、线程安全的栈、队列、查找表和链表之后,我们开始学习如何通过内存模型和原子操作实现无锁版本的线程安全的栈和队列(之前已实现无锁环形队列,这里实现的是两头进出的普通队列)。
参考:
【并发编程十五】无锁数据结构(1)——无锁栈 - DoubleLi - 博客园
风险指针(hazard pointer) - 纳姆德隆 - 博客园
1. 什么是无锁数据结构
锁的本质是阻止其他线程进入锁住的临界区,当一个线程在临界区中休眠,其他线程的操作也会被卡在临界区外(锁的根本意图就是杜绝并发功能,是阻塞型数据结构,但我们也可以实现基于锁的高并发线程安全的栈、队列、链表等其他数据结构,参考前面几节内容)。而无锁数据结构(非阻塞性数据结构)要求总有一个线程能够真正推进事情的进展,而不是空转,也就是说即使一些线程在任意位置休眠,其他线程也能完成操作并返回,这也说明任何时候都不存在锁住的临界区。
无锁数据结构不一定更快,因为常常需要很多原子操作,每个原子操作都有额外开销并可能涉及 CPU 和缓存的竞争。
无锁数据结构的优点:
- 最大限度地实现并发:
还是那句话,锁的根本意图就是杜绝并发功能,而无锁数据结构总存在某个线程能执行下一步操作(不存在锁的临界区导致其他线程被堵塞的问题)
- 代码的健壮性:
假设数据结构的写操作受锁保护,如果某一线程在持锁期间终止,那么该数据结构只完成了部分改动,且此后没办法修补。因为持锁期间,线程会对共享数据结构执行一系列被锁保护的操作,其他线程无法访问数据结构或观察到其部分修改状态,如果线程在操作完成之前终止(例如异常退出),锁会释放,但数据结构可能处于不一致或部分修改的状态,而剩下的部分操作没有其他线程可以接管和恢复操作,因为锁没有记录操作的上下文。
但是在无锁数据结构中,即使某线程操作无锁数据时意外终结,但丢失的数据仅限于它本身持有的部分,其他的数据仍然完好,能被其他线程正常处理(因为原子操作不能被分割,要么成功修改数据,要么失败保持原状态不变,所以即使线程终止,也不会留下半完成的修改)。
无锁数据结构的缺点:
- 难度大:
对无锁数据结构执行写操作的难度高于带锁的数据结构,主要因为无锁数据结构需要在没有锁的情况下依靠复杂的算法和原子操作(如CAS,就是compare_exchange_strong)来保证线程安全。写操作必须确保全局一致性,处理并发冲突,并设计有效的重试机制,同时解决诸如ABA问题等细节。而带锁数据结构只需通过互斥锁避免并发,逻辑相对简单,因此无锁写操作的实现通常更加复杂且易出错。
- 活锁
由于无锁数据结构完全不含锁,因此不存在死锁问题,但活锁(live lock)反而有可能出现。假设两个线程同时修改同一份数据结构,若他们所做的改动都导致对方从头开始操作,那双方就会反复循环,不断重试,这种现象即为活锁。与死锁不同,活锁中的线程不会被阻塞,它们会持续执行某些操作,但由于逻辑错误或相互之间的干扰,始终无法达到预期的目标。
2. 简单的无锁栈实现
2.1 原理解析
队列和栈最大的区别就是:栈是先入后出的,队列是先入先出的,如下图
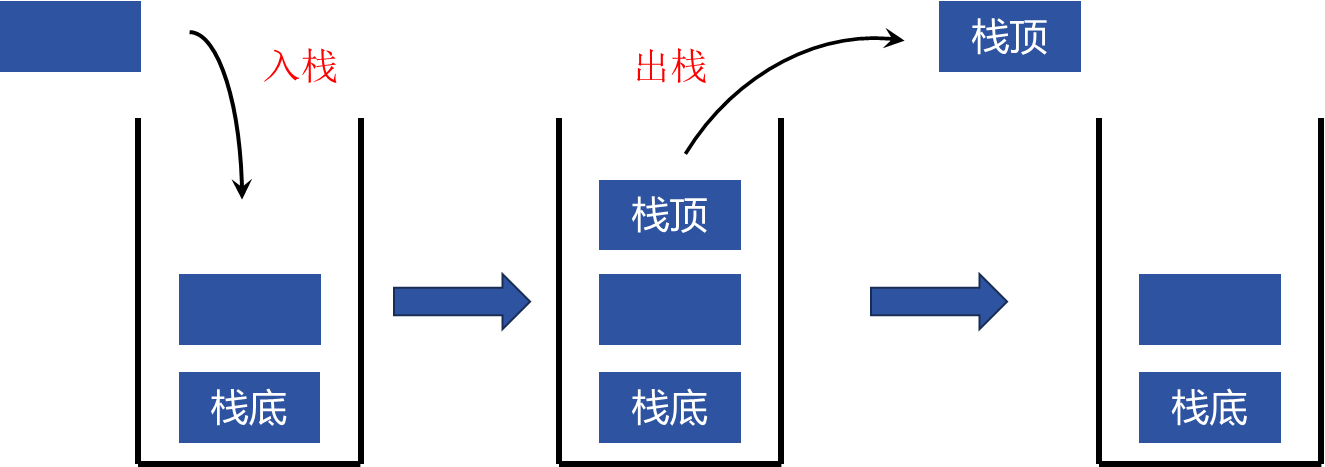

因为栈是先入后出的,因此我们必须保证:一旦某线程将一项数据加入栈容器,就能立即安全地被另一个线程去除,同时还得保证,只有唯一一个线程能获取该项数据(因为栈要求操作是顺序且唯一的,即栈顶元素一旦被移除,就不应该被其他线程获取)。
我们使用链表实现一个最简单的栈容器:指针 head 指向第一个节点(即将被取出的节点),各节点内的next成员指针再依次指向后继节点。
在单线程下 push 添加节点的流程如下:
- 创建新节点
- 将新节点的 next 指针指向当前的头节点(head 指针指向的节点 )
- 将 head 指针指向新节点(更新 head 指针)
但是在多线程下,如果有两个线程同时添加节点,步骤 2 和步骤 3 之间就会产生数据竞争:假设某线程完成了步骤 2,但尚未执行步骤 3,此时头节点还未更新,在此时另一个线程可能抢先改动 head 指针。
需注意,head 指针一旦被更新,那么其他线程就能读取。我们必须先对新节点做好一切修改之后才可能设置指针 head 指向它,而之后再也无法修改该节点的内部数据。
如果是按同步方式来优化,那么很简单,我们只需要设立一个临界区,当前有且仅有一个线程可以添加元素,其他线程会在到达该临界区前被挂起,直至 head 指针更新。
但我们这里使用无锁的本意是取代同步方式,那么我们可以考虑将步骤 3 该换为使用原子化的比较-交互操作,使 head 指针由步骤 2 读出后就不再改动。一旦发生改动,我们就循环重试。
2.2 代码实现
栈容器push() 的无锁实现如下:
1 | template<typename T> |
- 我们简单定义了一个结构体
node当作节点的存储结构,简单起见未用智能指针进行包装; - 拷贝构造、赋值运算符均被delete,并定义了一个类型为
std::atomic<node*>的 head 指针,使其可以使用原子操作对其进行修改; - push 函数的执行流程如下:
- 创建新节点 new_node
- 令新节点的成员指针 next 指向当前的头节点
- 将 head 指针指向新节点
这里我们使用
compare_exchange_weak做判断,确定 head 指针与 new_node->next 所存储的值是否相同,若相同,就将 head 指针改为指向 new_node,并返回true;若返回 false,则表明对比的两个指针互异(head 指针被其他线程修改过),第一个参数new_node->next就被更新成 head 的当前值。我们这里使用
compare_exchange_weak而不是compare_exchange_strong是原因是前者相比后者的开销更小,尽管前者可能会出现假失败(由于某些硬件的特性而出现假失败),但我们通过循环进行了重试。
类似的, pop() 的代码实现如下:
1 | template<typename T> |
尽管实现了基本的线程安全,但仍有以下三个问题:
没处理空栈的情况:如果 head 指针为空,而代码试图读取其 next 指针,就会导致未定义行为。我们只需要在while循环置为查验 head 指针是否为 nullptr,并且针对空栈抛出异常、布尔值或者空指针示意 pop 操作成功与否。
调用拷贝构造可能会导致数据丢失的问题,这个问题我们已经说了很多次了:如果复制返回值导致异常抛出,便会造成返回值丢失。针对这一情况,我们在使用同步方式时使用了两种方式解决(返回引用、返回智能指针),先将元素数据域取出赋值再出栈。
但在本节无锁实现时(无锁环形队列可以使用),返回引用的方式却不可取:因为仅当我们确认正在栈容器弹出节点的只有当前线程时,复制数据才是安全行为,矛盾之处在于,那样必须先移除栈顶节点(我们在实现本节无锁方式的栈容器时,pop数据必须先将数据按步骤 1 和 2 取出来以后才能使用步骤 3 赋值给引用变量,但是如果步骤 3 抛出异常,原本的数据已经被删除了,导致栈结构出错。)因此传入引用以取出返回值的方法不可取,我们仍旧以值的形式返回结果。
综上,我们可以使用另一个方法:返回一个智能指针,指向所获得的值
未释放弹出的节点的内存,导致内存泄漏。
为了避免发生以下情况:某线程删除了节点,而另一线程却仍持有指向该节点的指针,并要根据它执行取值操作。我们暂且不考虑内存泄漏的情况下,对 pop 函数进行修改:
1 | std::shared_ptr<T> pop() { |
上面这段代码实现了一个可能会泄漏节点内存的线程安全的无锁栈。
如果是其他语言(Java、C#)我们可以使用垃圾回收器来释放内存,以免内存泄漏,但是C++编译器不会提供垃圾回收器,我们必须手动清理:
1 | template<typename T> |
该段代码在 3 处定义了一个T类型的智能指针 res 用来返回 pop 的结果,所以在4处将old_head的data的内部控制块转移给res,这样就相当于清除old_head的data了。
在5处delete了old_head,旨在回收数据,但这存在很大问题,比如线程1执行到5处删除old_head,而线程2刚好执行到2处用到了和线程1相同的old_head指向的节点,线程2执行compare_exchange_weak的时候old_head->next会引发崩溃。
假如两个线程 t1 和 t2 同时执行 pop 函数,线程 t1 率先到达步骤 2 将 head 更新(此时线程 t2 已经取到 old_head),并且率先到步骤 5 将 old_head delete;当线程 t2 走到步骤 2 时,线程 t2 持有的 old_head 是已经被删除的指针,此时如果执行步骤 2编译器将会报错。因为我们需要将 old_head 和 old_head->next 传入 compare_exchange_weak,old_head 已经被delete,此时指向一个未知的空间,我们在传入 old_head->next 的时候因为找不到 next,会引发报错。
所以我们必须在删除某节点之前,先行确认其他线程并未持有指向该节点的指针,否则不得执行该操作。在一个栈容器实例上,如果只有一个线程曾经调用过 pop(),那么弹出的节点可安全地删除。因为全部节点都在 push 的调用过程中创建,而push 并不会访问已经存在于栈容器节点上的内容,所以仅仅两种线程可能访问指定结点,一是将其压入栈容器的线程(该线程在push完数据之后对该容器的此数据进行读取、修改),二是任何借 pop() 调用把它弹出的线程。
因此,我们可以考虑采取某种跟踪措施,判定何时才可以安全地删除节点。我们可以维护一个 “等待删除链表” (简称侯删链表),每次执行弹出操作都向它加入相关节点,等到没有线程调用 pop() 时,才删除侯删链表中的节点。我们可以采用对调用进行计数的方式:为 pop() 函数设置一个计数器,使之在进入函数时自增,在离开函数时自减,那么,当计数变为0时,我们就能安全删除侯删链表中的节点。该计数器必须原子化,才能实现多线程高并发访问。
侯删链表的原理可以理解为:
- 如果head已经被更新,且旧head不会被其他线程引用,那旧head就可以被删除。否则放入待删列表。
- 如果仅有一个线程执行pop操作,那么待删列表可以被删除,如果有多个线程执行pop操作,那么待删列表不可被删除。
我们实现该跟踪措施:
1 | std::shared_ptr<T> pop() { |
- 原子变量
threads_in_pop用于记录目前正有多少个线程试图从栈容器弹出数据,它在 pop() 函数的最开始处 ++,在 pop 即将结束时调用try_reclaim()自减,每当有节点被删除try_reclaim()便被调用依次,;to_be_deleted用于记录侯删链表的首节点。 try_reclaim()函数用于删除 old_head 或者将其放入待删列表,以及判断是否删除待删列表。
try_reclaim() 的内部实现如下:
1 | void try_reclaim(node* old_head) |
释放 old_head 节点分为两步:先释放侯删链表,再删除 old_head 节点
因为
threads_in_pop是原子变量,所以它的修改是线程安全的,当threads_in_pop == 1时代表仅有一个线程调用了pop()函数;当threads_in_pop != 1时,表明有其他线程也同时调用了 pop 函数,此时删除节点的行为不安全,需将该节点添加到侯删链表中- 如果
threads_in_pop == 1,此时我们没有调用原子变量的 load,也就是即便判断threads_in_pop值的时候其他线程也可以pop,这样不影响效率,即便模糊判断threads_in_pop为1,同一时刻threads_in_pop可能会增加也没关系,threads_in_pop为1仅表示当前时刻走入步骤 1 处逻辑之前仅有该线程执行pop,那说明没有其他线程竞争head,head已经被更新为新的值(调用try_reclaim时,head指针早已被更新),其他线程之后pop读取的head和我们要删除的old_head不是同一个,就是可以被直接删除的。 - 只有一个线程调用 pop() 函数的话,我们可以安全删除刚刚弹出的节点,而无需担心其他线程同时持有 old_head 的问题
- 如果
对
to_be_deleted调用exchange()函数,将其值更换为nullptr,并将to_be_deleted原本的值返回给nodes_to_delete。to_be_deleted被修改为空指针后,其他线程便无法通过该指针访问侯删链表,侯删链表的本体在通过nodes_to_delete访问,即侯删链表实际上被当前线程独占。然后调用 –threads_in_pop 自减(这一步是肯定会执行的,因为 –threads_in_pop 是 threads_in_pop = threads_in_pop - 1,且效自减结果立即生效),如果自减后计数器变为0,此时别的线程不会访问侯删链表中的节点,调用 delete_nodes() 函数遍历侯删链表,逐一删除等待删除的节点;
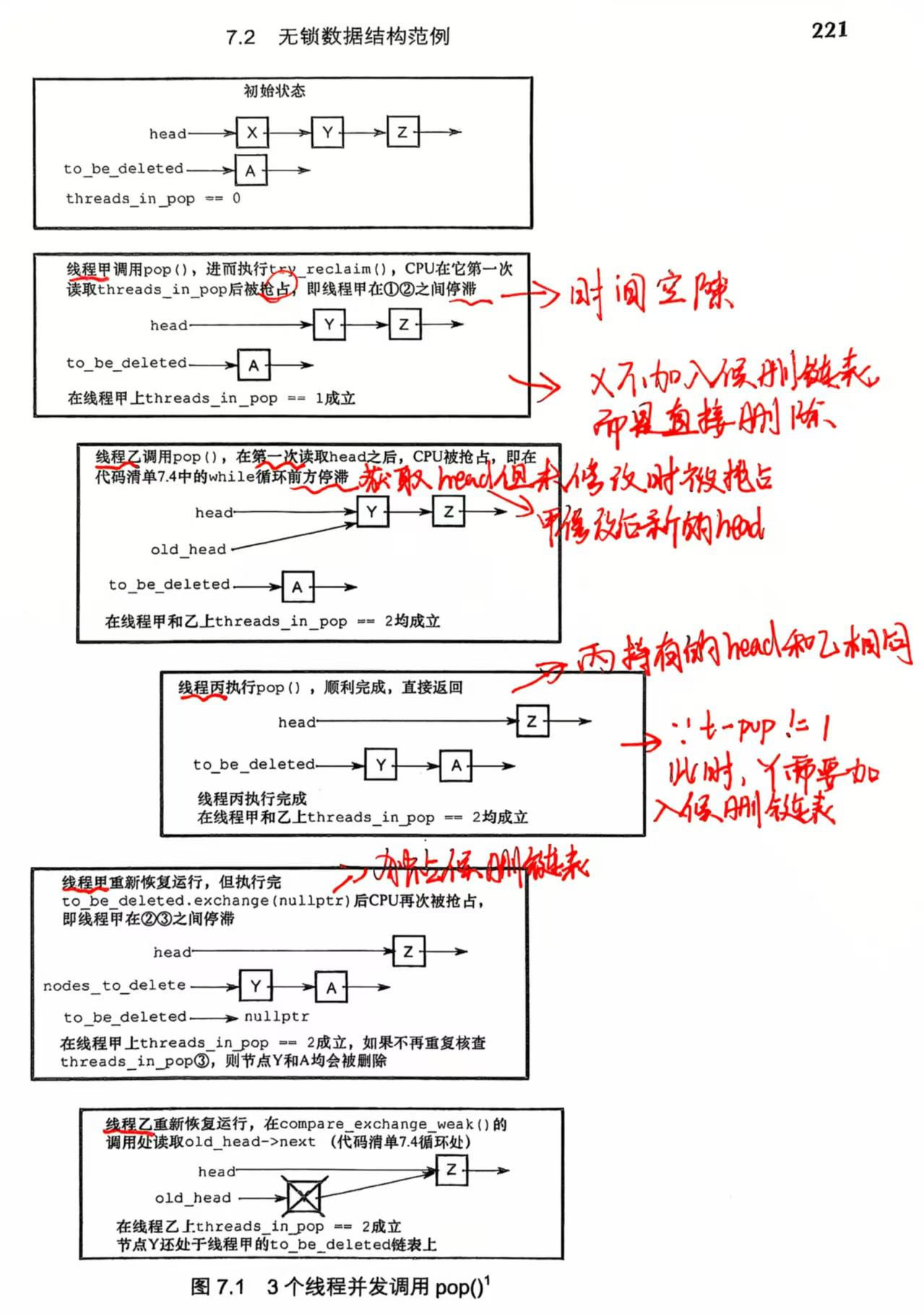
如果多个线程同时通过 pop() 访问栈容器时,有可能出现以下情况:
- 当前线程先检查完
threads_in_pop的值 1 后(如果threads_in_pop为1,侯删链表不加入 old_head 节点,而是直接删除,这样跳过了添加动作增加了效率),才将侯删链表独占 2,两项操作中间可能存在时间空隙,使别的线程乘机调用 pop 向侯删链表加入新的待删除的节点,此时可能有一些线程正在访问该节点,如下图所示。

- 我们此时需要重新判断 threads_in_pop 的值 3,如果自减后为 0,那么就可以安全无忧的删除侯删链表了,如果不为0,说明此种情况存在,我们不能直接删除nodes_to_delete,否则可能会导致其他线程的未定义行为,然后在 elseif 分支将 nodes_to_delete 重新加入侯删链表 to_be_deleted中。
- 然后将 old_head 释放,因为线程能进入到这里,那就代表仅有当前线程持有 old_head,无需担心其他线程还持有 old_head (其他线程可能会持有Y,但不可能持有X,因为当前线程调用try_reclaim时,head的值便已经更改,其他线程无法持有),可以直接删除 old_head,但不能将侯删链表删除。
- 当前线程先检查完
如果threads_in_pop不为1,说明有多个线程同时调用了pop,那么就将该节点加入之侯删链表,然后将 threads_in_pop - 1,当threads_in_pop == 0 时,便将侯删链表删除
delete_nodes() 函数用于遍历侯删链表,并逐一删除,实现如下:
1 | static void delete_nodes(node* nodes) |
chain_pending_node() 函数用于将节点放入侯删链表,实现如下:
1 | // 给定链表的头和尾,并将其放入侯删链表头 |
delete_nodes() 函数实现了三种重载:
- 第一种重载用于将给定表头和表尾的链表插入至侯删链表的表头。且因为 2 处可能因为其他线程修改了 to_be_deleted 或者因为硬件原因假失败,我i们采用循环直至匹配到
last->next的值为to_be_deleted为止,并将to_be_deleted更新为 first 的值,即达到了将给定表头和表尾的链表插入至侯删链表的表头的作用。 - 第二种重载用于将单个节点插入至侯删链表。
- 第三种重载用于将
nodes_to_delete为首的链表还原到待删列表中(步骤 5)
2.3 完整代码
1 |
|
简单的无锁栈实现存在一个问题:当多个线程执行 pop 操作时,被删除的节点会被添加到待删除列表中。如果 pop 操作频繁被多个线程调用,待删除的节点将不断累积,导致待删除列表无法及时回收,进而占用大量内存。为了解决这个问题,可以考虑让执行完 pop 操作的最后一个线程负责回收待删除列表。这个问题我们将在下一节通过风险指针进行优化。
3. 风险指针优化的无锁栈
无锁(Lock-free)对象相比传统的基于锁的对象,具有显著的性能和可靠性优势。但是,在实践中,如何有效回收这些对象中被删除的动态节点所占用的内存,仍然是无锁技术广泛应用的一个主要难题。目前缺乏一种既高效又可移植的无锁内存回收方法。
风险指针是一种专门用于内存管理的方法,它允许被回收的内存可以被安全地重用。这种方法是无等待的(wait-free),核心操作仅依赖单个内存单元的读取和写入,具有较高的效率。此外,风险指针还为ABA问题提供了一种无锁解决方案。
风险指针的基本思想是:当一个线程需要访问某个对象时,如果这个对象可能会被其他线程删除,那么该线程可以设置一个风险指针,指向这个对象,告诉其他线程“这个对象正在被使用,暂时不要删除”。一旦程序不再需要这个对象时,该风险指针会被清除,表示这个对象可以被安全删除了。
在指针管理方面,我们应主要关注如何回收已删除对象所占用的内存。在基于锁的设计中,当一个线程删除某个节点后,很容易确保在节点被重用或重新分配之前,没有其他线程会访问该节点的内存。但在无锁动态对象中,由于线程之间没有锁的约束,为了保证无锁对象能够正确执行,必须确保每个线程在任何时间都能自由操作该对象,这也使得内存回收变得更加复杂。
3.1 如何实现
首先,我们需要确定存储风险指针的内存区域,这样才能通过这个指针安全地访问目标节点。这块内存区域必须对所有线程可见,并且每个线程都有自己专属的风险指针,用来访问栈中的节点。如何正确且高效地分配这块内存是一个难点,我们将在后文详细讨论。这里,我们暂时假设已经有一个现成的函数 get_hazard_pointer_for_current_thread(),它负责为当前线程生成一个风险指针,并返回它的引用。接下来,当我们需要通过风险指针访问目标节点时,只需将这个风险指针设置为目标节点的地址即可。
风险指针的设置部分代码如下:
1 | std::shared_ptr<T> pop() |
步骤 1 用于为当前线程生成一个风险指针,并用类型为
std::atomic<void*>的引用变量 hp 存储。注意:void*是一种不确定类型的指针,可以指向任意类型的对象,但不能直接进行解引用操作,必须先转换为目标类型的指针才能解引用。步骤 2 获取当前栈的头节点,并存储至 old_head 中
步骤 3 用于将风险指针 hp 设置为 old_head 指向节点的地址;注意:这里需要重新加载头指针,用于检查其是否被其他线程修改。
因为步骤 2 和步骤 3 之间存在时间空隙,在这一时间窗口内,其他线程均无法得知当前线程正在访问该节点(因为此时风险指针还没有设置为目标节点,其他线程没办法得知该线程正在使用,可能会将其删除)。如果此时旧的头节点
old_head被其他线程删除,那么head指针就会被更新,指向新的节点。因此,我们需要不断地对比风险指针和当前的头指针:
- 如果
head指针和风险指针指向的节点不一致,就重新加载head,并将风险指针再次设置为新的头指针的值。 - 这个过程会持续循环,直到
head指针和风险指针在步骤 4 中保持一致为止,确保我们安全地捕获到一个有效的节点。
如果多个线程同时调用 pop 函数,某一个线程B将head修改,说明它早已经将它的临时变量old节点放入风险数组中(风险指针的的设置在弹出元素和更新head之前),而本线程A的old节点和线程B的old节点指向的是同一个旧有的head,所以线程A就没必要将这个old节点放入风险数组了,需要再次循环获取新的head加载为old节点,再放入风险数组。
- 如果
接下来,我们可以继续处理 pop 函数的剩下部分。
1 | std::shared_ptr<T> pop() |
- 步骤 1 和步骤 2 用于设置风险指针,以告诉其他回收线程“这个节点正在被使用,暂时不要删除”
- 步骤 3 用于将旧的头节点从栈中取出,并更新 head 指针的值,这样只有当前取出旧头节点的线程才能通过 old_head 变量访问旧头节点,相当于独占
- 步骤 4 用于将旧头节点的风险指针清零,表示“当前线程已不再使用旧头节点,其他线程可以删除”
- 步骤 5 中,如果 old_head 指向的旧头节点被成功 pop 出,必须先检查它是否正被其他线程的风险指针所指涉,若被指涉,该节点不能被立即删除,而需按步骤 6 放入侯删链表中留待稍后回收;否则,按步骤 7 立即删除它。
- 最后,在步骤 8 中核查由 reclaim_later() 回收的所有节点,如果其中有一些节点不再被任何线程的风险指针所指涉,即可安全删除。剩余被指涉的节点在下一个线程调用 pop() 时,会被再次按同样的方式被处理。
get_hazard_pointer_for_current_thread() 函数的作用是为每个线程分配一个风险指针,并为它分配内存空间。我们可以自由选择具体的内存分配及布局方案,这不会影响程序的核心逻辑,但后文将阐明这会影响到运行效率。
为了简单起见,我们可以设计一个结构体 hazard_pointer,用来将线程的 ID 和对应的风险指针绑定在一起。然后,将这些结构体存储在一个固定大小的数组中。
这个函数的工作流程如下:
- 查找空位:函数会在数组中找到一个空闲位置。
- 分配指针:将找到的位置分配给当前线程,并将该位置结构体中的线程 ID 设置为当前线程的 ID。
- 线程结束时释放:当线程结束时,函数会将该位置的线程 ID 重置为默认值(通过
std::thread::id()创建的默认 ID),释放这个位置供其他线程使用。
代码实现如下:
1 | // 风险指针结构体 |
结构体和全局风险指针数组便不再解释,上面说的清晰。这里解释一下 get_hazard_pointer_for_current_thread:
thread_local关键字用于指示线程局部存储,表示 hazzard 是每个线程独有的变量;且每个线程在首次调用时,会初始化自己的 hazzard 实例,不同线程之间互不影响、互相独立static保证hazzard在当前线程内的生命周期贯穿整个线程的生命周期hp_owner类型是我们自定义的一个类,主要用于管理线程危险指针,后文会介绍hp_owner类的成员函数get_pointer()主要是返回结构体hazard_pointer的pointer成员的引用
hp_owner 类的具体实现如下:
1 | class hp_owner { |
- 因为
hazzard是线程局部静态变量,只有每个线程在第一次调用get_hazard_pointer_for_current_thread()函数时才会构造hp_owner类型的hazzard变量;且hp_owner的拷贝构造和赋值运算符被delete,移动拷贝和移动赋值运算符由于 3/5/0法则 被隐式阻止生成,所以只有在第一次调用get_hazard_pointer_for_current_thread()函数时才会调用默认构造创建hazzard。 - 在默认构造函数中,先将风险指针 hp 置为 nullptr(表示尚未分配到任何风险指针);然后遍历全局风险指针数组,寻找空闲的风险指针,max_hazard_pointers 是全局风险指针数组的最大数量;如果找到空闲的风险指针,即将
hazard_pointers[i].id与old_id(初始为空 ID)比较,如果相等(该位置为空闲风险种子很),则将其更新为当前线程 ID。- 如果成员分配,则将该指针的地址存储到
hp中,并退出循环。如果循环结束后仍未分配到危险指针,抛出异常,说明系统中没有可用的危险指针。
- 如果成员分配,则将该指针的地址存储到
- 在析构函数中,首先将当前线程的风险指针
hp置为 nullptr(表示该指针不再指向任何内存位置);然后将危险指针的id字段重置为空 ID(std::thread::id()),表示该危险指针已空闲,可以被其他线程使用。 - get_pointer() 函数简单的返回结构体的 pointer 成员。注意:风险指针的类型是 std::atomic<void^>&,在使用前需要将 void* 转换为对应的类型
outstanding_hazard_pointers_for() 函数用于检查给定节点是否正被其他线程的风险指针所指涉,如果指涉则返回 true,反之 false。实现如下:
1 | bool outstanding_hazard_pointers_for(void* p) |
- 很简单,遍历全局风险指针数组,判断给定节点 p 是否存储于风险指针数组中,如果存在返回 true,反之 false。
如果当前节点被风险指针所指涉,调用reclaim_later() 函数将给定节点放入侯删链表延迟删除
1 | void reclaim_later(node* old_head) { |
data_to_reclaim 类型是自定义的结构体,用于存储侯删链表的节点,实现如下:
1 | struct data_to_reclaim { |
data用于存放待删除的节点next用于指向下一个待删除的节点deleter是一个删除器,该删除器可以容纳一个返回值为void,形参类型为node*的可调用对象,用于删除data。如果不使用,则调用默认析构函数。
然后在无锁栈中定义一个节点表示侯删链表的首节点,因为栈是被多个线程操作的,侯删链表也会被多个线程访问,那么我们需要用原子变量表示这个首节点:
1 | std::atomic<data_to_reclaim*> nodes_to_reclaim; |
add_to_reclaim_list() 函数用于将待删节点加入至侯删链表中,实现如下:
1 | void add_to_reclaim_list(data_to_reclaim* reclaim_node) { |
- 实现很简单,就算将给定节点的 next 指针指向侯删链表的表头,即
nodes_to_reclaim存储的节点;指向之后更新nodes_to_reclaim为reclaim_node,表示侯删链表最新的表头节点
delete_nodes_with_no_hazards() 函数用于在 pop 函数结束前删除侯删链表中无其他线程风险指针指涉的节点,
1 | void delete_nodes_with_no_hazards() { |
- 首先,将侯删链表的首节点设置为 nullptr,并将其旧值返回给局部指针变量 current。只有当前线程才能通过 current 访问到之前的侯删链表,而其他线程只能访问到在此之后的侯删链表,可以理解为当前线程独占。
- 然后,迭代侯删链表,依次查看侯删链表的每个节点是否有被其他线程的风险指针所指涉
- 如果没指涉,直接将其 delete
- 反之,将该节点重新添加至侯删链表中
3.2 完整代码
1 |
|
回忆一下我们为什么要使用风险指针:如果 pop 操作频繁被多个线程调用,待删除的节点将不断累积,导致待删除列表无法及时回收,进而占用大量内存。此时我们需要一种机制,每次调用 pop 函数结束后都需要判断侯删链表中的节点是否可以被 delete,风险指针的作用就是这个。
但在一开始实现风险指针的时候我们就说过:如何正确且高效地分配这块内存是一个难点。
此外风险指针还有一些操作也会导致额外的性能开销:为了删除一个节点,需要遍历风险指针数组,检查该节点是否被某个风险指针引用。同时,在处理待删除节点时,也需要从风险数组中选取合适的节点记录其地址,这进一步增加了开销。
而且因为该方法受专利保护,所以在一些场合可能无法使用,下一节我们学校如何通过引用计数来实现无锁栈以及安全回收机制。