二十、day20 在实现无锁栈中,我们使用了风险指针 和双引用计数 两种方式实现内存回收机制,我们同样也可以使用上面两种方式在无锁队列进行内存安全回收,这里举例双引用计数方式 的无锁栈原理实现。
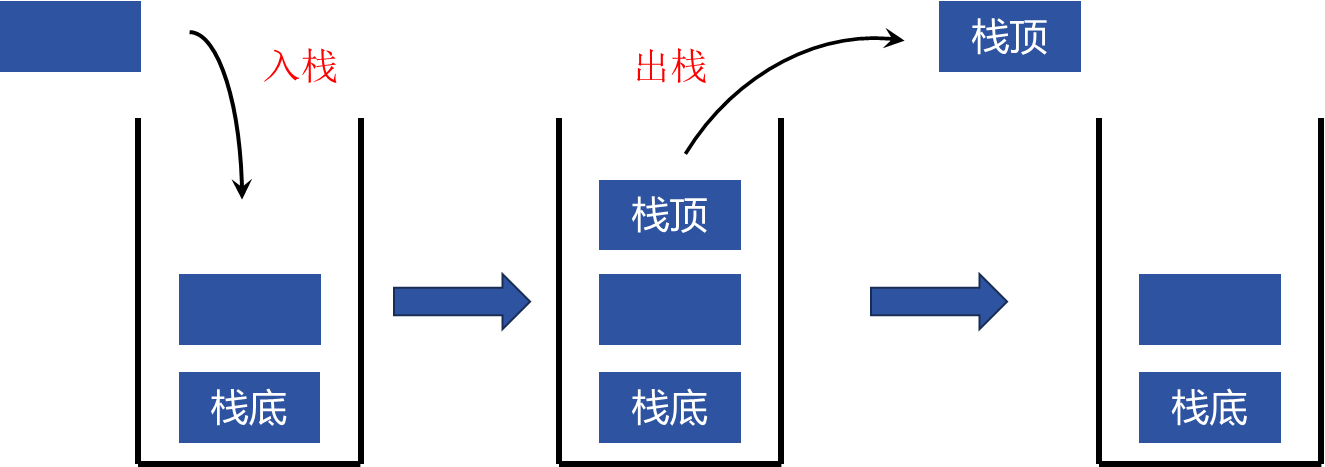
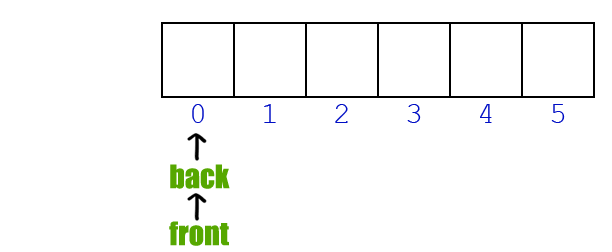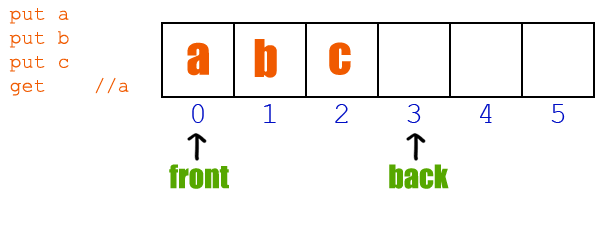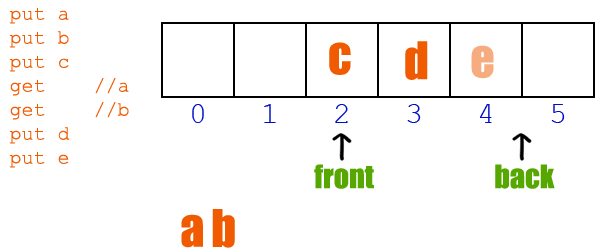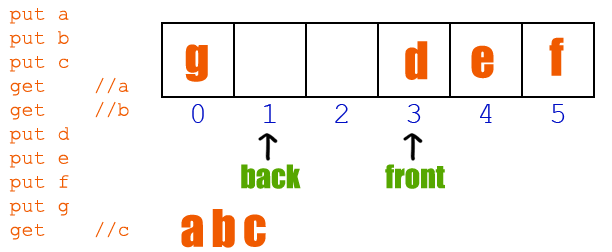
队列和栈最大的区别就是:栈是先入后出的,队列是先入先出 的,如下图
栈:先入后出
队列:先入先出
因为队列是先入先出的,当队头元素被pop或队尾增加新元素后,头节点和尾节点指针必须做相应的变化,如下所示:
图片来源:https://developer.aliyun.com/article/1325615
队列和栈容器的难点有一些不同,因为对于队列结构,push() 和 pop() 分别访问其不同部分,而在栈容器上,这两项操作都访问头节点,所以两种数据结构所需的同步操作相异。如果我们要通过某一线程在队列一端做出改动(弹出或压入),那么其他线程若同时访问队列另一端,则必须保证前者的改动过程能正确被后者看到。
我们在前面学习基于锁的队列时,使用了两个节点指针,分别指向头、尾节点,用来控制数据的弹出或压入,并且队首和队尾使用了不同的互斥进行数据的保护,可参考文章:并发编程(15)——基于同步方式的线程安全的栈和队列 | 爱吃土豆的个人博客 。在本节中,我们使用原子变量取代对应的互斥,确保多线程并发调用下,能保证队列的线程安全。
举例:
恋恋风辰官方博客
【深度长文】还是没忍住,聊聊神奇的无锁队列吧!-阿里云开发者社区
1. 支持单一生产和和单一消费者的无锁队列 我们首先实现仅支持单一生产和和单一消费者 的无锁队列,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <atomic> #include <memory> template <typename T>class SinglePopPush { private : struct node { std::shared_ptr<T> data; node* next; node () : next (nullptr ) {} }; std::atomic<node*> head; std::atomic<node*> tail; node* pop_head () { node* const old_head = head.load (); if (old_head == tail.load ()) { return nullptr ; } head.store (old_head->next); return old_head; } public : SinglePopPush () : head (new node), tail (head.load ()) {} SinglePopPush (const SinglePopPush& other) = delete ; SinglePopPush& operator =(const SinglePopPush& other) = delete ; ~SinglePopPush () { while (node* const old_head = head.load ()) { head.store (old_head->next); delete old_head; } } std::shared_ptr<T> pop () { node* old_head = pop_head (); if (!old_head) { return std::shared_ptr <T>(); } std::shared_ptr<T> const res (old_head->data) ; delete old_head; return res; } void push (T new_value) { std::shared_ptr<T> new_data (std::make_shared<T>(new_value)) ; node* p = new node; node* const old_tail = tail.load (); old_tail->data.swap (new_data); old_tail->next = p; tail.store (p); } };
pop_head() 函数用于弹出队首的元素(因为队列是先入先出的,所以必须是弹出 head 指向的节点),原理很简单:当 head 和 tail 指向同一个内存空间时,表示当前队列无数据,返回空指针,反之,返回队首元素。 但注意 ,在该函数中,我们仅仅只是将元素数据从链表中去除,但并没有 delete(这部分在 pop 函数中通过引用计数 安全回收内存)
push()和 pop() 也很简单,不过多叙述。但注意,我们这里仅实现了智能指针方式的 pop 函数,其实在队列中可以实现返回引用版本的 pop 函数(在前面无锁栈的学习过程中,我们仅可以通过智能指针的方式实现 pop 函数,因为在无锁版本栈容器的实现中,是先将元素从链表中去除,然后才将元素赋值,所以可能会引发问题,而在锁栈容器中pop有两种实现方式)
在上面的代码中,同一时刻如果只有一个线程 t1 调用 push(),且仅有一个线程 t2 调用 pop(),这份代码可以线程安全的执行,因为 head 和 tail 不存在数据竞争问题(存在先行关系 )。
先行关系确保push() 的数据写入必然早于 pop() 的数据读取,我们顺一下这段代码中的先行关系 :在线程 t1 调用 push() 中,操作 5 顺序先行于操作 7 ;在线程 t2 调用 pop() 中,操作 1 顺序先行于操作 2 。因为必须先压入数据之后我们才可以弹出,且因为原子操作默认使用CS模型 (先后一致性模型),所以线程 t1 先于线程 t2 运行,则操作5 ->操作7 ->操作1 ->操作2 ,即操作5 先行于操作1 ,线程 t1 中操作5 的修改对线程 t2 中操作2 必定可见,所以该单一生产者、单一消费者(Single-Producer Single-Consumer,SPSC)队列可以完美地工作。
关于内存模型和内存次序的关系可参考文章:并发编程(11)——同步、先行关系 | 爱吃土豆的个人博客 和并发编程(12)——内存次序与内存模型 | 爱吃土豆的个人博客 。
不过,若多个线程 并发调用push()或并发调用pop(),便会出问题。我们先来分析push()。如果有两个线程同时调用push(),就会分别构造一个新的空节点并分配内存3 ,而且都从tail指针读取相同的值4 ,结果它们都针对同一个尾节点更新其数据成员,却各自把data指针和next指针设置为不同的值5和6。这形成了数据竞争!
pop_head()也有类似问题,若两个线程同时调用这个函数,它们就会读取同一个头节点而获得相同的next指针,而且都把它赋予head指针以覆盖head指针原有的值。最终两个线程均认为自己获取了正确的头节点,这是错误的根源。给定一项数据,我们不仅要确保仅有一个线程可对它调用pop(),如果有别的线程同时读取头节点,则还需保证它们可以安全地访问头节点中的next指针。
我们曾在前文的无锁栈容器中遇见过类似问题,其pop()函数也有完全相同的问题,我们可以直接采用无锁栈中的解决方法实现无锁队列的pop函数,但是push函数如何实现呢?
2. 支持多线程并发的push()函数 push() 函数的问题的关键在于队列上的 push() 和 pop() 必须构成先行关系 (我们需要保证push() 在存储 tail 之前完成数据写入,pop() 在读取数据之前完成了对 tail 的加载),所以我们需要先构造出空节点并向它存入数据,然后才更新 tail 指针。但是依据这种模式,若代码多线程并发调用 push() ,则多线程会同时读取 tail 指针,结果在同一个数据上形成竞争。
解决办法以下两种:
在两个真实节点之间加入空节点 。按此处理,当前尾节点只需要更新 next 指针即可完成操作,并通过原子操作保证线程安全。当某个线程成功将当前节点的 next 从 nullptr 更新为指向新节点时,节点就被成功加入队列;否则(当前节点的 next 已被更新),线程需重新读取 tail 并重试。同时,pop() 需要忽略空节点并继续循环操作。其缺点是每次调用 pop() 通常都需删除两个节点,所占用的内存大小也是普通方法的两倍。将data指针原子化 。通过 CAS 操作来设置它的值。如果比较-交换操作成功,所操作的节点即为真正的尾节点,我们便可安全地设定next指针,使之指向新节点。若比较-交换操作失败,就表明有另一线程同时存入了数据,我们应该进行循环,重新读取tail指针并从头开始操作。
为了节约资源,我们采用第二种方法。如果std::shared_ptr<>上的原子操作是无锁实现,那便万事大吉,但事实上 std::shared_ptr<> 仅在控制块中的原子操作是无锁实现,具体解释可参考文章C++——智能指针剖析 | 爱吃土豆的个人博客 。一种可行的解决方法是令pop()返回std::unique_ptr<>指针(凭此使之成为指涉目标对象的唯一指针),并在队列中存储指向数据的普通指针。这样让代码得以按std::atomic<T*>的形式存储指针,支持必要的compare_exchange_strong()调用。
因为 pop() 函数的内存回收机制通过引用计数实现,push() 函数也需要做相应的修改(初始化空节点的引用计数为1),push() 的实现如下:
这里将 head 和 tail 的类型选择 std::atomic<counted_node_ptr> 副本类型而不是指针,具体解释可参考无锁栈的文章
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void push (T new_value) std::unique_ptr<T> new_data (new T(new_value)) ; counted_node_ptr new_next; new_next.ptr=new node; new_next.external_count=1 ; for (;;) { node* const old_tail=tail.load (); T* old_data=nullptr ; if (old_tail->data.compare_exchange_strong ( old_data,new_data.get ())) { old_tail->next=new_next; tail.store (new_next.ptr); new_data.release (); break ; } } }
在 push() 函数中,我们只需对空节点的引用计数初始化为1 ,后续基于引用计数的内存回收机制在 pop() 函数中实现。
head 和 tail 指向真正存储数据的节点 node,而不是指向和数据节点解耦的引用技术快。我们在操作 2 中,判断当前队列的尾指针 tail 指向节点的数据是否为空(如果为空说明尾指针还未更新或已更新完毕,如果不为空说明尾指针指向的内存块已经存储了新数据,但尾指针尚未更新,我们需要等待尾指针更新完毕),如果为空则将需将需要压入的数据传递给当前尾指针指向的节点(这里为了保证数据的独占性,将数据内容交给 unique_ptr 管理,我们传递给数据节点的是 unique_ptr 管理数据的裸指针 ),然后将当前尾指针指向节点的 next 指向新建立的下一个节点的引用计数快,并更新尾指针指向一个空的数据节点。最后,我们需要释放一开始为了存储数据而创建的 unique_ptr 类型的节点 new_data。
在释放 unique_ptr 时,为了只放弃所有权而不销毁管理的对象,需要调用 release() 而不能调用 reset()。
我们在实现支持单一生产和单一消费无锁队列时,tail 在push 函数最后更新,并在 pop 函数中最先调用(相比data数据的存储或读取),但是我们在按这种方式实现多线程并发无锁队列时,存在一个风险:
假设存在线程 t1 、t2 和 t3
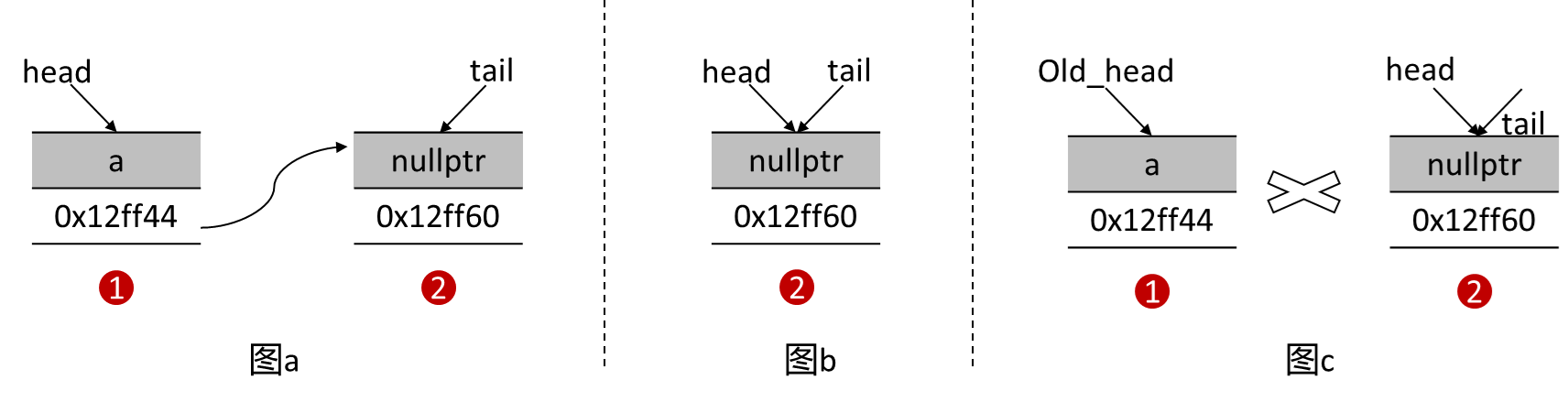
线程 t1 执行pop函数,线程t2和线程t3执行push函数,如果线程t2和t3同时调用push函数并执行到操作1 处读取相同 的tail值,若线程t2率先将数据a压入队列,并更新了 tail 的值。此时队列情况如图a所示。
若线程t1此时调用了pop函数抢占了时间片,线程t3停在操作2 处,此时线程t1将数据a弹出并将节点1 删除(因为只有线程t1调用了pop函数,在pop函数中判断的该节点的外部计数器为2,一个初始化加的1,一个线程t1加的1,此时满足删除条件会将该节点直接删除,即使线程t3仍旧把持着该节点,但因为push函数没有办法和pop函数中的外部引用计数器共享,所以线程t3对该节点的引用没办法为线程t1所见。而且push函数中也没有一个额外的计数器能供它加1,两个计数器只用于pop函数),最后更新了head,此时情况如图b所示。
但在线程t2中,我们已经将tail的旧值读取(即指向节点1 的值),如图c所示。在引用计数无锁栈中,我们通过引用计数成功的保护了栈中每个节点,但是队列不像栈一样是单向的,队列的头和尾很难进行共享(因为头和尾的类型是 std::atomic<ref_node>,是副本 类型,节点内的引用计数很难共享,所以我们必须针对队列额外增加一个外部计数器)
如果此时线程t2执行操作2 ,因为old_tail已经读取,CAS 操作成功,但因为节点1 已经被delete(引用计数没有保护tail指针指向的节点),而线程t2对节点1 的操作会引发未定义行为。
为了解决该问题,我们需要为增加一个额外的计数器 供 push 函数使用(其实是供 tail指针使用),这样线程1在调用 pop 函数时,如果有其他线程在 push 函数中引用了该节点,那么该计数器可为线程1可见,就不会造成误删情况。
新实现的链表节点和 push 函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 template <typename T>class lock_free_queue { private : struct node ; struct counted_node_ptr { int external_count; node* ptr; }; std::atomic<counted_node_ptr> head; std::atomic<counted_node_ptr> tail; struct node_counter { unsigned internal_count:30 ; unsigned external_counters:2 ; }; struct node { std::atomic<T*> data; std::atomic<node_counter> count; counted_node_ptr next; node () { node_counter new_count; new_count.internal_count=0 ; new_count.external_counters=2 ; count.store (new_count); next.ptr=nullptr ; next.external_count=0 ; } void release_ref () }; public : void push (T new_value) std::unique_ptr<T> pop () ; };
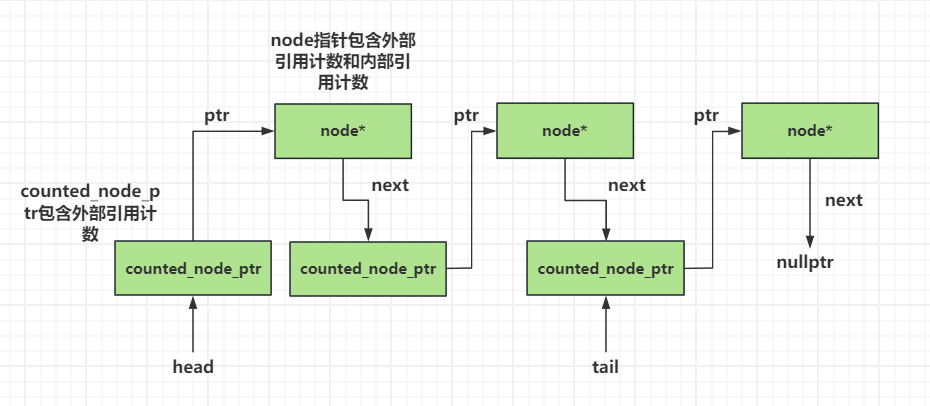
counted_node_ptr 为外部计数器,即增计数器,在 pop 函数中,如果有其他线程持有 head 或 tail 指向的节点,那么会加 1;node 为数据节点,保存队列数据内容以及两个计数器(一个为本来就有的减计数器,一个是供 push 函数使用的额外计数器);node_counter 保存了 node 的两个计数器,其中 external_counters 仅需要两位,它表示被不同指针指涉的个数(和其他两个计数器不同,external_counters 作用于指针而不是不同线程);internal_count 其实就是减计数器。
external_counters 被分配了一个两位的位域,而 internal_count 被分配了30位的整型值,从而维持了计数器32位(4字节)的整体尺寸。按此处理,内部计数器的取值范围仍然非常大,还保证了在32位或64位计算机上,一个机器字(machine word)便能容纳整个结构体。只要把结构体的大小限制在单个机器字内,那么在许多硬件平台上,其原子操作就更加有机会以无锁方式实现。
在 node 的构造函数中,我们将 internal_count 初始化为 0(减计数器默认是 0),将 external_counters 初始化为 2(因为我们向队列加入的每个新节点,它最初既被tail指针 指涉,也被前一个节点的next指针 指涉),并将下一个节点的外部计数器初始化为 0,至于 node 节点本事的外部计数器 external_count,则在使用的时候会默认初始化为 1。
push() 函数的代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void push (T new_value) std::unique_ptr<T> new_data (new T(new_value)) ; counted_node_ptr new_next; new_next.ptr=new node; new_next.external_count=1 ; counted_node_ptr old_tail=tail.load (); for (;;) { increase_external_count (tail,old_tail); T* old_data=nullptr ; if (old_tail.ptr->data.compare_exchange_strong ( old_data,new_data.get ())) { old_tail.ptr->next=new_next; old_tail=tail.exchange (new_next); free_external_counter (old_tail); new_data.release (); break ; } old_tail.ptr->release_ref (); } }
首先,将数据存储至一个独占指针中,用于暂时保存数据内容;然后初始化一个外部计时器 new_next,且 new_next 的 ptr 成员指向与该计时器绑定的用于存储数据的节点 node,external_count 默认初始化为 1 ;最后读取 tail 当前指向的节点(如果没有其他线程干涉,此时 tail 指向 nullptr)
至此,初始化工作便完成,接下来需要完成数据的压入操作。
在循环中,首先调用函数 increase_external_count() 令外部计数器增加,具体实现后面介绍;然后通过 CAS 操作将与 tail 指针指向的外部计数器与之绑定的数据节点 node 指向需要存储的内存块(这里通过调用智能指针的get函数返回其管理数据的原生指针),如果判断成功,说明没有其他线程干涉。
在 if 分支中,首先将一开始初始化的 new_next 作为下一个节点的外部计数器交给 old_tail.ptr 指向(我们在每次压入数据时都需要将一个节点的外部计时器先定义好,并让数据节点的next指针指向它);然后将尾指针 tail 更新,此时 tail 指向 nullptr(其实它的外部计时器已经初始化好了,但是数据节点仍未初始化,是 nullptr)。
在 7 处,调用函数 free_external_counter 释放 old_tail 的计数,最后调用独占指针的 release() 函数释放该指针但不销毁管理对象。
如果没有执行 if 分支,即有其他线程干涉,那么就释放当前线程对当前节点内部计数器的引用并重重试
三种计数器对节点的管理方式如下图所示:
图片来源:https://llfc.club/category?catid=225RaiVNI8pFDD5L4m807g7ZwmF#!aid/2ahHZgMOCIfy9TnBOaS8pXKjf5n
3. 减少引用计数的函数 3.1 release_ref() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void node::release_ref () node_counter old_counter = count.load (std::memory_order_relaxed); node_counter new_counter; do { new_counter = old_counter; --new_counter.internal_count; } while (!count.compare_exchange_strong ( old_counter, new_counter, std::memory_order_acquire, std::memory_order_relaxed)); if (!new_counter.internal_count && !new_counter.external_counters) { delete this ; } }
release_ref() 函数是数据节点 node 的一个公有函数,主要功能是减少对象对内部计数器的引用计数,并在内部计数器和额外计数器全部归零时销毁对象。如果一些线程同时调用 push 函数,但同一时刻有且仅有一个线程才能抢占节点,其他未抢占到节点的线程会调用该函数释放其对抢占节点的引用。
首先,获取抢占节点的计数块,计数块内包含一个内部计数器以及我们额外加的一个计数器,并赋值给 old_counter;因为 old_counter、new_counter都是副本 类型,所以需要通过 CAS 操作将每个线程对抢占节点的引用减一(内部计数器减一);
然后,判断抢占节点计数块的两个计数器是否都为0,如果为零表示没有其他线程或指针占用该节点,可以销毁当前对象。
我们在这个函数中仅更新了 internal_count,而 external_counters 是我们额外加的计数器,需要在其他函数中更新。
3.2 increase_external_count() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static void increase_external_count ( std::atomic<counted_node_ptr>& counter, counted_node_ptr& old_counter) counted_node_ptr new_counter; do { new_counter=old_counter; ++new_counter.external_count; } while (!counter.compare_exchange_strong ( old_counter,new_counter, std::memory_order_acquire,std::memory_order_relaxed)); old_counter.external_count=new_counter.external_count; }
increase_external_count() 函数是无锁栈对象的一个静态成员函数,因为它需要更新的目标不再是自身固有的成员计数器,而是一个外部计数器,它通过第一个参数传入函数以进行更新,安全地增加给定节点的外部引用计数。
参数列表中第一个形参类型是 std::atomic<counted_node_ptr> 的引用,也就是 tail 和 head 类型的引用;第二个参数类型是与每个数据节点绑定的外部计数块类型 counted_node_ptr 的引用;在 push 函数中,我们一般这样调用:increase_external_count(tail, tail.load());
然后通过 do-while 调用 CAS 操作更新外部计数器,每个线程都会让它 +1,所以无论在 push 还是 pop 函数中,increase_external_count 函数必须首先调用,为了防止其他线程删除占用的节点。
3.3 free_external_counter() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 static void free_external_counter (counted_node_ptr &old_node_ptr) node* const ptr=old_node_ptr.ptr; int const count_increase=old_node_ptr.external_count-2 ; node_counter old_counter= ptr->count.load (std::memory_order_relaxed); node_counter new_counter; do { new_counter=old_counter; --new_counter.external_counters; new_counter.internal_count+=count_increase; } while (!ptr->count.compare_exchange_strong ( old_counter,new_counter, std::memory_order_acquire,std::memory_order_relaxed)); if (!new_counter.internal_count && !new_counter.external_counters) { delete ptr; } }
与 increase_external_count() 对应的是 free_external_counter() 函数,前者用于增加外部计数器的引用数,后者用于将前者加的值减去,该函数对整个计数器结构体仅执行一次 CAS ,便合并更新了其中的两个计数器(3处),这与 release_ref() 中更新 internal_count 的自减操作类似。该函数一般在函数打破循环时调用:free_external_counter(tail.load())或free_external_counter(head.load())。
首先,获取传入节点的数据域,并赋值给 ptr;然后获取其他线程对传入节点的引用数 count_increase,减去 2 是因为先要减去当前线程以及初始化的两个 1,一共2,剩下的便是其他线程对该节点的引用数;
获取传入节点数据域的内部计数块,并赋值给 old_counter;然后通过 CAS 操作先减去每个线程对它的引用(external_counters 在 数据节点 node 中初始化为 2,因为我们向队列加入的每个新节点,它最初即被tail指针指涉,也被前一个节点的next指针指涉),并将其他线程对传入节点的引用数加在内部计数器 internal_count 上,具体原因可参考上一节无锁栈。
因为 internal_count 和 external_counters 绑定在一起,所以这里需要通过 CAS 操作绑定更新,最后判断这两个值是否都为0 ,如果为零,表示传入节点可删除。
4. 支持多线程并发的pop()函数 pop() 函数的实现和无锁栈的类似,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 std::unique_ptr<T> pop () counted_node_ptr old_head=head.load (std::memory_order_relaxed); for (;;) { increase_external_count (head,old_head); node* const ptr=old_head.ptr; if (ptr==tail.load ().ptr) { ptr->release_ref (); return std::unique_ptr <T>(); } if (head.compare_exchange_strong (old_head,ptr->next)) { T* const res=ptr->data.exchange (nullptr ); free_external_counter (old_head); return std::unique_ptr <T>(res); } ptr->release_ref (); } }
队列的 pop 和栈的 pop 不同,栈是后入先出,通过读取、存储 head 即可实现数据的 pop 和 push;但队列是先入先出的,我们从 tail 后加入新元素,从 head 弹出元素。
我们先获取当前 head 指针指向的引用计数块,然后进入 for 循环进行自旋弹出操作:
在 2 处,对已加载好指针的外部计数器进行自增(+1),在无锁栈中我们通过 do-while 实现,这里我们将这个过程封装为一个函数 increase_external_count;
在 3 处,进行空栈判断,不同的是我们在返回空智能指针前需要将引用器释放;
在 4 处,更新 head 节点,如果更新未成功,说明存在其他线程干涉,需自旋重试;如果更新成功,head 指向下一个节点的引用计数块,当前线程就顺利地将节点所属的数据收归己有。然后当前线程将弹出节点的数据传给局部变量 res,并将弹出节点清空;
在 5 处,我们随即释放弹出节点的外部计数器,并构造一个智能指针存储数据并将其返回;
在 6 处,如果在 4 处更新失败,我们需要减少内部计数器,并判断数据域的计数块是否都被释放,若内部计数块值均为0,则节点本身可被删除。
5. 优化 虽然上述代码尚可工作,也无条件竞争,但依然存在性能问题。一旦某线程开始执行 push() 操作,针对 old_tail.ptr->data 成功完成了 CAS 调用(push代码6 处),就没有其他线程可以同时运行push()。若有其他任何线程试图同时压入数据,便始终看不到nullptr,而仅能看到上述线程执行push()传入的新值,导致 CAS 调用失败,最后只能重新循环。这实际上是忙等,消耗CPU周期却一事无成,结果形成了实质的锁。第一个push()调用令其他线程发生阻塞,直到执行完毕才解除,所以这段代码不是无锁实现。
问题不止这一个。若别的线程被阻塞,则操作系统会提高对互斥持锁的线程的优先级,好让它尽快完成,但本例却无法依此处理,被阻塞的线程将一直消耗CPU周期,等到最初调用push()的线程执行完毕才停止。
我们结合代码看一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void push (T new_value) std::unique_ptr<T> new_data (new T(new_value)) ; counted_node_ptr new_next; new_next.ptr=new node; new_next.external_count=1 ; counted_node_ptr old_tail=tail.load (); for (;;) { increase_external_count (tail,old_tail); T* old_data=nullptr ; if (old_tail.ptr->data.compare_exchange_strong ( old_data,new_data.get ())) { } old_tail.ptr->release_ref (); } }
假设多个线程同时调用 push():
线程 A 成功完成了 6 处的 CAS 操作(将 nullptr 替换为 new_data)。
此时,old_tail.ptr->data 不再是 nullptr,而是线程 A 的 new_data。
线程 B 尝试执行同样的 CAS 操作,因 old_tail.ptr->data 已经是线程 A 的值,线程 B 的 CAS 会失败。
如果线程 A 因为一些原因导致在 if 分支中始终未更新 tail,那么线程 B 会一直处于自旋重试的状态,因为 tail 在线程 A 中未更新,所以线程 B 每次读取的 old_tail.ptr->data 都是 new_data,而不是 nullptr,那么线程 B 会一直自旋重试。结果是多个线程虽然可以同时运行 push(),但只有一个线程可以有效推进操作,其他线程处于忙等状态,实际上是被阻塞 的。
为了解决这个问题,可以让等待的线程协助当前执行 push() 操作的线程,从而实现真正的无锁队列。具体方法是:先将尾节点的 next 指针设置为指向一个新的空节点,并立即更新 tail 指针。由于所有空节点的结构都相同,它的来源无关紧要,可以由成功压入数据的线程创建,也可以由其他等待中的线程生成。通过使用原子操作 compare_exchange_strong() 设置 next 指针,确保更新过程的线程安全性。一旦 next 指针设置完成,就可以用 compare_exchange_weak() 配合循环更新 tail 指针。如果在尝试更新时发现 tail 指针已被其他线程修改,就不再继续重试,从而避免浪费资源。
5.1 pop() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 template <typename T>class lock_free_queue { private : struct node { std::atomic<T*> data; std::atomic<node_counter> count; std::atomic<counted_node_ptr> next; }; public : std::unique_ptr<T> pop () { counted_node_ptr old_head=head.load (std::memory_order_relaxed); for (;;) { increase_external_count (head,old_head); node* const ptr=old_head.ptr; if (ptr==tail.load ().ptr) { return std::unique_ptr <T>(); } counted_node_ptr next=ptr->next.load (); if (head.compare_exchange_strong (old_head,next)) { T* const res=ptr->data.exchange (nullptr ); free_external_counter (old_head); return std::unique_ptr <T>(res); } ptr->release_ref (); } } };
next 指针的类型被修改为 std::atomic<counted_node_ptr> 而不是之前的 counted_node_ptr,并且 2 处的载入操作也成了原子操作。本例使用了默认的 memory_order_seq_cst 次序,而 ptr->next 指针原本属于 std::atomic<counted_node_ptr> 型别,在 2 处隐式转化 成 counted_node_ptr 型别,这将触发原子化的载入(load)操作,故无须显式调用 load()。不过我们还是进行了显式调用,目的是提醒自己,在以后优化时此处应该显式设定内存次序。
5.2 push() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 template <typename T>class lock_free_queue { private : void set_new_tail (counted_node_ptr &old_tail, counted_node_ptr const &new_tail) public : void push (T new_value) { std::unique_ptr<T> new_data (new T(new_value)) ; counted_node_ptr new_next; new_next.ptr=new node; new_next.external_count=1 ; counted_node_ptr old_tail=tail.load (); for (;;) { increase_external_count (tail,old_tail); T* old_data=nullptr ; if (old_tail.ptr->data.compare_exchange_strong ( old_data,new_data.get ())) { counted_node_ptr old_next={0 }; if (!old_tail.ptr->next.compare_exchange_strong ( old_next,new_next)) { delete new_next.ptr; new_next=old_next; } set_new_tail (old_tail, new_next); new_data.release (); break ; } else { counted_node_ptr old_next={0 }; if (old_tail.ptr->next.compare_exchange_strong ( old_next,new_next)) { old_next=new_next; new_next.ptr=new node; } set_new_tail (old_tail, old_next); } } } };
优化后的 push 函数主要增加了 else 分支,如果在第 6 处 失败,说明其他线程已经抢先设置了 data,当前线程进入 else 分支,执行协作逻辑。在 else 分支中,失败线程会尝试协助设置 next 指针:判断抢占线程是否已经完成了操作 7 , 更新了 tail 指针,如若还未更新,那么操作 11 会将 push 函数一开始为 tail 下一个节点初始化好的引用计数块设置为当前 tail 指针的 next 指针。同时,分配一个新数据节点(13 处)以供后续插入操作使用,最后调用 set_new_tail() 函数更新 tail 指针。
如果操作 7 失败,若我们便知道另一线程同时抢先协助设定了 next 指针,遂无须保留函数中最初分配的新节点,可以将它删除(8处),然后通过操作 9 将其他协助线程设立的 next 指针取到手。
一旦 data 和 next 指针的更新完成,就需要更新队列的尾指针(tail)。set_new_tail() 函数用于更新 tail 指针,它接受两个参数,第一个参数是更新前的尾节点,第二个参数是已设置的 next 指针,这两个参数都是 counted_node_ptr 类型,而不是数据域。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void set_new_tail (counted_node_ptr &old_tail, counted_node_ptr const &new_tail) node* const current_tail_ptr=old_tail.ptr; while (!tail.compare_exchange_weak (old_tail,new_tail) && old_tail.ptr==current_tail_ptr); if (old_tail.ptr==current_tail_ptr) free_external_counter (old_tail); else current_tail_ptr->release_ref (); }
在 2 处,使用 compare_exchange_weak() 原子性地更新尾指针,如果 tail 已被其他线程更新,则循环停止,避免无意义的重复尝试。举个例子:假如协助线程还未更新 tail 指针,那么在 2 处的 CAS 操作会成功,!True 会让循环退出,主线程更新 tail 成功;假如协助线程已更新 tail 指针,那么 old_tail 会被更新为新的 tail 值,后面的 old_tail.ptr != current_tail_ptr,循环同样会退出。
如果 ptr 没有变化,即协助线程未更新 tail(3 处),说明 tail 已被主线程正确更新,则释放原有的外部计数器(4 处)。如果 ptr 发生变化,则说明另一个线程已释放计数器(协助线程也会调用该函数,如果协助线程先调用,那么会更新 tail 并执行 4 处释放了计数器,我们这里不需要再次释放了),因此当前线程仅需要释放持有的尾节点指针(5 处)。
5.3 完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 #pragma once #include <atomic> #include <memory> #include <cassert> template <typename T>class lock_free_queue { private : struct node_counter { unsigned internal_count : 30 ; unsigned external_counters : 2 ; }; struct node ; struct counted_node_ptr { counted_node_ptr ():external_count (0 ), ptr (nullptr ) {} int external_count; node* ptr; }; struct node { std::atomic<T*> data; std::atomic<node_counter> count; std::atomic<counted_node_ptr> next; node (int external_count = 2 ) { node_counter new_count; new_count.internal_count = 0 ; new_count.external_counters = external_count; count.store (new_count); counted_node_ptr node_ptr; node_ptr.ptr = nullptr ; node_ptr.external_count = 0 ; next.store (node_ptr); } void release_ref () { std::cout << "call release ref " << std::endl; node_counter old_counter = count.load (std::memory_order_relaxed); node_counter new_counter; do { new_counter = old_counter; --new_counter.internal_count; } while (!count.compare_exchange_strong ( old_counter, new_counter, std::memory_order_acquire, std::memory_order_relaxed)); if (!new_counter.internal_count && !new_counter.external_counters) { delete this ; std::cout << "release_ref delete success" << std::endl; destruct_count.fetch_add (1 ); } } }; std::atomic<counted_node_ptr> head; std::atomic<counted_node_ptr> tail; void set_new_tail (counted_node_ptr& old_tail, counted_node_ptr const & new_tail) { node* const current_tail_ptr = old_tail.ptr; while (!tail.compare_exchange_weak (old_tail, new_tail) && old_tail.ptr == current_tail_ptr); if (old_tail.ptr == current_tail_ptr) free_external_counter (old_tail); else current_tail_ptr->release_ref (); } static void free_external_counter (counted_node_ptr& old_node_ptr) { std::cout << "call free_external_counter " << std::endl; node* const ptr = old_node_ptr.ptr; int const count_increase = old_node_ptr.external_count - 2 ; node_counter old_counter = ptr->count.load (std::memory_order_relaxed); node_counter new_counter; do { new_counter = old_counter; --new_counter.external_counters; new_counter.internal_count += count_increase; } while (!ptr->count.compare_exchange_strong ( old_counter, new_counter, std::memory_order_acquire, std::memory_order_relaxed)); if (!new_counter.internal_count && !new_counter.external_counters) { destruct_count.fetch_add (1 ); std::cout << "free_external_counter delete success" << std::endl; delete ptr; } } static void increase_external_count ( std::atomic<counted_node_ptr>& counter, counted_node_ptr& old_counter) { counted_node_ptr new_counter; do { new_counter = old_counter; ++new_counter.external_count; } while (!counter.compare_exchange_strong ( old_counter, new_counter, std::memory_order_acquire, std::memory_order_relaxed)); old_counter.external_count = new_counter.external_count; } public : lock_free_queue () { counted_node_ptr new_next; new_next.ptr = new node (); new_next.external_count = 1 ; tail.store (new_next); head.store (new_next); std::cout << "new_next.ptr is " << new_next.ptr << std::endl; } ~lock_free_queue () { while (pop ()); auto head_counted_node = head.load (); delete head_counted_node.ptr; } void push (T new_value) { std::unique_ptr<T> new_data (new T(new_value)) ; counted_node_ptr new_next; new_next.ptr = new node; new_next.external_count = 1 ; counted_node_ptr old_tail = tail.load (); for (;;) { increase_external_count (tail, old_tail); T* old_data = nullptr ; if (old_tail.ptr->data.compare_exchange_strong ( old_data, new_data.get ())) { counted_node_ptr old_next; counted_node_ptr now_next = old_tail.ptr->next.load (); if (!old_tail.ptr->next.compare_exchange_strong ( old_next, new_next)) { delete new_next.ptr; new_next = old_next; } set_new_tail (old_tail, new_next); new_data.release (); break ; } else { counted_node_ptr old_next ; if (old_tail.ptr->next.compare_exchange_strong ( old_next, new_next)) { old_next = new_next; new_next.ptr = new node; } set_new_tail (old_tail, old_next); } } construct_count++; } std::unique_ptr<T> pop () { counted_node_ptr old_head = head.load (std::memory_order_relaxed); for (;;) { increase_external_count (head, old_head); node* const ptr = old_head.ptr; if (ptr == tail.load ().ptr) { ptr->release_ref (); return std::unique_ptr <T>(); } counted_node_ptr next = ptr->next.load (); if (head.compare_exchange_strong (old_head, next)) { T* const res = ptr->data.exchange (nullptr ); free_external_counter (old_head); return std::unique_ptr <T>(res); } ptr->release_ref (); } } static std::atomic<int > destruct_count; static std::atomic<int > construct_count; }; template <typename T>std::atomic<int > lock_free_queue<T>::destruct_count = 0 ; template <typename T>std::atomic<int > lock_free_queue<T>::construct_count = 0 ;