Task 2 Aggregation & Join Executors 在实现了最基本的 insert、scan、update 等算子之后,我们需要在 task2 中实现三个最核心并且比较复杂的三个算子:Aggregation 、NestedLoopJoin 和 NestedIndexJoin,从而实现聚合和连接操作。
Aggregation Aggregation 采用基于哈希表的分组聚合算法,核心思想是将具有相同分组键的元组映射到哈希表的同一个桶中,并在该桶中维护相应的聚合状态,从而在单次遍历输入数据的情况下完成所有分组的聚合计算。
Aggregation 的实现中定义了一个专门的 SimpleAggregationHashTable 类,该类封装了聚合操作所需的所有核心功能,以此维护一个从 AggregateKey 到 AggregateValue 的映射关系:
1 2 3 4 5 6 std::unordered_map<AggregateKey, AggregateValue> ht_{}; const std::vector<AbstractExpressionRef> &agg_exprs_;const std::vector<AggregationType> &agg_types_;
在映射表 ht_ 中,AggregateKey 包含了所有 GROUP BY 的表达式的值,而 AggregateValue 则存储了各个聚合函数的中间结果。光看代码很难立即它的作用,举个例子说明:
假设我们有以下 SQL 查询:
1 2 3 SELECT department, COUNT (* ), SUM (salary), MAX (age)FROM employeesGROUP BY department
对于这个查询, AggregateKey = {department 的值},比如{“Engineering”};AggregateValue = {COUNT(*)、UM(salary)和 MAX(age)的值},比如{5, 20000, 35}。
假如我们处理的第一条记录为:("Qiaobeibei", "Engineering", 8000, 25),首先提取分组键 department = “Engineering”,然后创建 AggregateKey{“Engineering”}。因为映射表 ht_ 初始不存在该键对应的值,调用 GenerateInitialAggregateValue() 函数进行初始化(COUNT(*) 初始化为0,SUM(salary) 初始为NULL,MAX(age)初始为NULL),然后调用 CombineAggregateValues() 并集(COUNT(*) = 0 + 1 = 1,SUM(salary) = NULL + 8000 = 8000, MAX(age) = NULL vs 25 = 25)。映射表的状态如下:
1 {"Engineering"} -> {1, 8000, 25}
然后处理第二天记录 ("Beauqiao", "Engineering", 9000, 24),同样提取分组键 department = “Engineering”,因为映射表中已经存在了该键,直接合并:COUNT(*) = 1 + 1 =2, SUM(salary) = 8000 + 9000 = 17000, MAX(age) = max(25, 24) = 25。映射表修改为:
1 {"Engineering"} -> {2, 17000, 25}
继续处理第三天记录 ("Baby", "Marketing", 7000, 24),提取分组键 同样提取分组键 department = “Marketing”,因为是新的分组,需要创建新条目:COUNT(*) = 0 + 1 = 1, SUM(salary) = NULL + 7000 = 7000, MAX(age) = NULL vs 25 = 25。映射表最终为:
1 2 {"Engineering"} -> {2, 17000, 25} {"Marketing"} -> {1, 7000, 25}
在这个过程中,agg_exprs_ 负责存储所有聚合表达式,以此告诉系统对哪些列或表达式进行聚合,而 agg_types_ 存储了相应的聚合类型,告诉系统执行怎么样的聚合操作,比如 COUNT、SUM或者MAX。
同样是上面的例子,("Qiaobeibei", "Engineering", 8000, 25),首先提取聚合值:
1 2 3 agg_exprs_[0]->Evaluate(tuple) -> 1 (COUNT(*)总是1) agg_exprs_[1]->Evaluate(tuple) -> 8000 (salary列的值) agg_exprs_[2]->Evaluate(tuple) -> 25 (age列的值)
得到 AggregateValue{1, 8000, 25},然后合并聚合值:
1 2 3 4 5 6 7 8 9 10 11 12 13 for (uint32_t i = 0 ; i < agg_exprs_.size (); ++i) { switch (agg_types_[i]) { case AggregationType::CountStarAggregate: break ; case AggregationType::SumAggregate:: break ; case AggregationType::MaxAggregate: break ; } }
最后将键值插入到映射表 ht_ 中。
简而言之,**agg_exprs_[i] 告诉系统如何从输入元组中提取到第 i 个聚合函数所需要的值;agg_types_[i] 决定了对第 i 个值执行什么的操作;二者通过索引 i 将表达式和聚合类型关联起来,保证每个聚合函数都能正确输入和处理逻辑;最后按分组键映射所有聚合计算结果到 ht_ 的不同桶中。**
了解了 SimpleAggregationHashTable 之后,Aggregation 的实现就比较容易懂。和 update、insert、delete 算子一样,它也是从子执行器获取需要处理的数据,然后从 aht_ 中获取数据逐行处理 。
在 Init 阶段,Aggregation 需要遍历子执行器产生的所有元组,对每个元组提取分组键和聚合值,然后调用 InsertCombine 方法将其插入到哈希表中(如果分组键已存在,则将当前元组的聚合值与已有值进行合并;否则创建新的聚合条目并初始化为默认值)。
在 Next 阶段,Aggregation 使用迭代器遍历哈希表中的所有聚合结果,每次调用 Next 时,执行器从当前迭代器位置获取一个聚合结果,将分组键和聚合值组合输出元组。特别注意的是,对于没有 GROUP BY 子句的聚合查询,当输入为空时,系统需要返回初始聚合值。例如 COUNT(*) 应该返回 0,而 SUM、MIN、MAX 等函数应该返回 NULL。
实现中通过 switch 对不同聚类类型进行分发处理,每种聚合函数都有专门的合并逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 auto AggregationExecutor::Next (Tuple *tuple, RID *rid) -> bool if (plan_->GetGroupBys ().empty () && aht_.Begin () == aht_.End ()) { if (initial_value_output_) { return false ; } auto initial_val = aht_.GenerateInitialAggregateValue (); std::vector<Value> values; for (const auto &group_by_expr : plan_->GetGroupBys ()) { (void )group_by_expr; } for (const auto &agg_val : initial_val.aggregates_) { values.push_back (agg_val); } *tuple = Tuple{values, &GetOutputSchema ()}; *rid = RID{}; initial_value_output_ = true ; return true ; } if (aht_.Begin () == aht_.End ()) { return false ; } if (!aht_iterator_valid_) { return false ; } if (aht_iterator_ == aht_.End ()) { return false ; } auto agg_key = aht_iterator_.Key (); auto agg_val = aht_iterator_.Val (); std::vector<Value> values; for (const auto &group_by_val : agg_key.group_bys_) { values.push_back (group_by_val); } for (const auto &agg_val_item : agg_val.aggregates_) { values.push_back (agg_val_item); } *tuple = Tuple{values, &GetOutputSchema ()}; *rid = RID{}; ++aht_iterator_; return true ; }
NestedLoopJoin
src/execution/nested_loop_join_executor.cpp
Join 的本质是将两个或者多个表中的数据按照某种条件关联起来,形成一个新的结果集,基本思想是找到满足连接条件的元组对,然后将这些元组组合成新的元组。连接操作有多种类型:
内连接(INNER JOIN):只返回满足连接条件的元组对
左外连接(LEFT JOIN):返回左表的所有元组,如果右表没有匹配的元组,则右表部分用NULL值填充
右外连接(RIGHT JOIN):返回右表的所有元组,如果右表没有匹配的元组,则右表部分用NULL值填充
全外连接(FULL OUTER JOIN)返回两个表的所有元组,不匹配的部分用NULL填充
NestedLoopJoin 是最基础的连接算子,其原理简单直观:对左表的每个元组,遍历右表的所有元组,检查连接条件是否满足 。虽然算子的时间复杂度为O(m*n),但在小表连接、缺乏合适索引或连接条件比较复杂的情况下比较适用。
在 NestedLoopJoin 的实现中,我们只需要实现内连接和左外连接即可,右外连接和全外连接可以通过左外连接和输入顺序调整来间接实现()。NestedLoopJoin 的伪代码如下:
1 2 3 4 for outer_tuple in outer_table: for inner_tuple in inner_table: if inner_tuple matched outer_tuple: emit
相应的,在 NestedLoopJoinExecutor 类中声明如下私有成员遍变量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 const NestedLoopJoinPlanNode *plan_;std::unique_ptr<AbstractExecutor> left_executor_; std::unique_ptr<AbstractExecutor> right_executor_; Tuple left_tuple_{}; RID left_rid_{}; bool left_tuple_available_{false };bool left_matched_{false };
对照着伪代码,实现流程如下:
left_executor_ 产生左表元组 -> 存储到 left_tuple_对于这个 left_tuple_,right_executor_ 遍历所有右表元组
如果找到匹配,设置 left_matched_ = true
处理完所有右表元组后,检查 left_matched_ 状态
如果是 LEFT JOIN 且 left_matched_ = false,输出左表元组 + NULL
移动到下一个左表元组(仅 left_tuple_available_ = true 时才可以移动),重置 left_matched_ = fasle
NestedLoopJoinExecutor 接收两个子执行器分别产出左、右测输入,并在 Next 中以双层循环驱动连接,。初始化阶段同时调用左右子执行器的Init,随后拉取首个左侧元组并清空匹配状态。
Next 阶段在外层”左元组可用“循环内,对应内层通过右侧子执行器拉去右元组并即时评估连接谓词,若为真则拼接输出;当右侧扫描完毕仍无匹配且为左外连接,则输出左侧元组配合右侧列的NULL值。每处理完一个左元组,重置右侧子执行器并推进到下一个左元组,直至左侧耗尽,实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 auto NestedLoopJoinExecutor::Next (Tuple *tuple, RID *rid) -> bool while (true ) { if (is_left_tuple_over_) { if (!left_executor_->Next (tuple, rid)) { return false ; } left_tuple_ = *tuple; is_left_tuple_over_ = false ; is_match_ = false ; } Tuple right_tuple{}; while (right_executor_->Next (&right_tuple, rid)) { Value value = plan_->Predicate ()->EvaluateJoin (&left_tuple_, left_executor_->GetOutputSchema (), &right_tuple, right_executor_->GetOutputSchema ()); if (value.IsNull () || !value.GetAs <bool >()) { continue ; } std::vector<Value> values; for (uint32_t i = 0 ; i < left_executor_->GetOutputSchema ().GetColumnCount (); i++) { values.emplace_back (left_tuple_.GetValue (&(left_executor_->GetOutputSchema ()), i)); } for (uint32_t i = 0 ; i < right_executor_->GetOutputSchema ().GetColumnCount (); i++) { values.emplace_back (right_tuple.GetValue (&(right_executor_->GetOutputSchema ()), i)); } *tuple = Tuple (values, &GetOutputSchema ()); is_match_ = true ; return true ; } is_left_tuple_over_ = true ; if (!is_match_ && plan_->GetJoinType () == JoinType::LEFT) { std::vector<Value> values; for (uint32_t i = 0 ; i < left_executor_->GetOutputSchema ().GetColumnCount (); i++) { values.emplace_back (left_tuple_.GetValue (&(left_executor_->GetOutputSchema ()), i)); } for (uint32_t i = 0 ; i < right_executor_->GetOutputSchema ().GetColumnCount (); i++) { values.emplace_back ( ValueFactory::GetNullValueByType (right_executor_->GetOutputSchema ().GetColumn (i).GetType ())); } *tuple = Tuple (values, &GetOutputSchema ()); right_executor_->Init (); return true ; } right_executor_->Init (); }
实现过程中需要注意以下几点:
谓词求值的复杂性体现在对多列表达式与NULL语义的支持,若直接将表达式值视为 bool 而忽略 NULL,将漏匹配。通过 Evaluation 在左右两侧模式之上评估表达式,并在落地时以 !value.IsNull() && value.GetAs<bool> 统一为 bool,避免了三值逻辑导致的误判。
左外连接的语义落地依赖于细粒度的匹配状态管理:left_matched_ 在首次匹配时置为真,右侧耗尽后检查其值,若仍为 false则按模式动态构造右侧列对应类型的NULl并输出;这要求从右侧输出模式中逐列提取类型,并用ValueFactory::GetNullValueBytypes 构造占位。
处理完一个左元组后,需要重置右侧执行器 。
可能到这里你还是对 Join 有些难以理解,举个例子来将代码和真实操作关系起来:
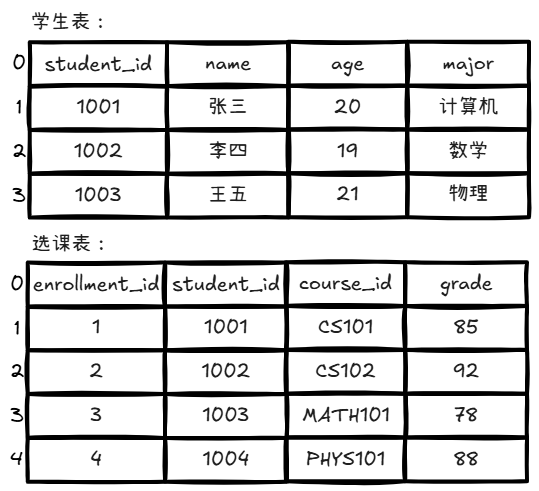
假设现在有两个表:
现在想要找出每个学生及其选课信息。SQL 如下:
1 2 3 SELECT s.name, s.major, e.course_id, e.gradeFROM students sLEFT JOIN enrollments e ON s.student_id = e.student_id;
NestedLoopJoin 的流程如下:
第一步 :处理 student_id = 1001
外层循环:获取张三的信息(name=”张三“,major=”计算机“)
内层循环:扫描选课表,寻找 student_id = 1001 的元组
找到元组{CS101, 85} and {CS102, 92}
拼接左表和右表元组的值,如下图
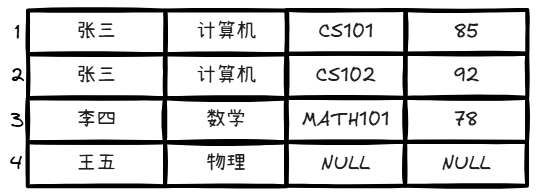
第二步 :处理 student_id = 1002
外层循环:获取李四的信息(name=”李四“,major=”数学“)
内层循环:扫描选课表,寻找 student_id = 1002 的元组
拼接左表和右表元组的值,如下图
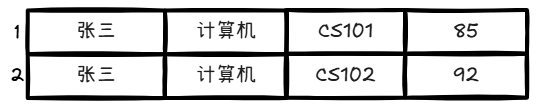
第三步 :处理 处理 student_id = 1003,流程如上,最后拼接结果值。
如果找的 student_id 在右表不存在呢,假如右表不存在student_id = 1003这个记录对应的值呢?左表的所有行保留,和右表连接(右表无匹配补NULL),结果如下:
NestedIndexJoin
src/execution/nested_index_join_executor.cpp
参考 :在进行 equi-join 时,如果发现 JOIN ON 右边的字段上建了 index,则 Optimizer 会将 NestedLoopJoin 优化为 NestedIndexJoin。具体实现和 NestedLoopJoin 差不多,只是在尝试匹配右表 tuple 时,会拿 join key 去 B+Tree Index 里进行查询。如果查询到结果,就拿着查到的 RID 去右表获取 tuple 然后装配成结果输出。
NestedIndexJoin 的简要概括如上述引用所述,其核心思想是以外表为驱动,逐行从外表产出元组,用该行通过连接键表达式计算出索引值,直接在内表的索引上做点查找获取候选RID,再回表取出内表元组并与外表元组拼接输出;若为左外连接且无匹配,则以NULL补齐到内表列后输出外表元组。与纯 NLJ 相比,区别只在”匹配右表元组“的环节,不再循环遍历右表,而是借助 ScanKey 在索引中把可能匹配缩小为确切匹配,将内层循环的代价从O(右表的大小)降到O(log N + k)。
Init 阶段完成子执行器启动、外表首行拉去与首轮索引探测:对第一条外表元组,通过计划节点的 KeyPredicate 在外表输出模式上求值得到索引键,按内表索引的 key_schema_ 构造键元组并调用 ScanKey 取回所有匹配的 RID,缓存至 inner_rids_ 供 next 使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void NestedIndexJoinExecutor::Init () child_executor_->Init (); outer_tuple_available_ = child_executor_->Next (&outer_tuple_, &outer_rid); outer_matched_ = false ; inner_rids_.clear (); inner_match_idx_ = 0 ; if (outer_tuple_available_) { auto catalog = exec_ctx_->GetCatalog (); auto index_info = catalog->GetIndex (plan_->GetIndexOid ()); auto key_value = plan_->KeyPredicate ()->Evaluate (&outer_tuple_, child_executor_->GetOutputSchema ()); std::vector<Value> key_values{key_value}; Tuple index_key{key_values, &index_info->key_schema_}; index_info->index_->ScanKey (index_key, &inner_rids_, exec_ctx_->GetTransaction ()); } }
Next 阶段先吐完当前外表行的所有匹配,然后再推进下一外表行。若 inner_rids_ 仍有未消费匹配,则逐个回表取元组,跳过已删除记录,设置匹配标志并与外表行拼接输出;当匹配耗尽且未LEFT JOIN且尚未匹配,则构造内表列对应类型的NULL与外表行拼接输出;否则推进到下一条外表行并立即为其做新一轮索引探测:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 auto NestedIndexJoinExecutor::Next (Tuple *tuple, RID *rid) -> bool auto catalog = exec_ctx_->GetCatalog (); auto inner_table_info = catalog->GetTable (plan_->GetInnerTableOid ()); auto index_info = catalog->GetIndex (plan_->GetIndexOid ()); while (outer_tuple_available_) { if (inner_match_idx_ < inner_rids_.size ()) { auto inner_rid = inner_rids_[inner_match_idx_++]; auto [tuple_meta, inner_tuple] = inner_table_info->table_->GetTuple (inner_rid); if (tuple_meta.is_deleted_) { continue ; } outer_matched_ = true ; std::vector<Value> values; for (uint32_t i = 0 ; i < child_executor_->GetOutputSchema ().GetColumnCount (); i++) { values.push_back (outer_tuple_.GetValue (&child_executor_->GetOutputSchema (), i)); } for (uint32_t i = 0 ; i < plan_->InnerTableSchema ().GetColumnCount (); i++) { values.push_back (inner_tuple.GetValue (&plan_->InnerTableSchema (), i)); } *tuple = Tuple{values, &GetOutputSchema ()}; *rid = RID{}; return true ; } if (plan_->GetJoinType () == JoinType::LEFT && !outer_matched_) { std::vector<Value> values; for (uint32_t i = 0 ; i < child_executor_->GetOutputSchema ().GetColumnCount (); i++) { values.push_back (outer_tuple_.GetValue (&child_executor_->GetOutputSchema (), i)); } for (uint32_t i = 0 ; i < plan_->InnerTableSchema ().GetColumnCount (); i++) { auto & column = plan_->InnerTableSchema ().GetColumn (i); values.push_back (ValueFactory::GetNullValueByType (column.GetType ())); } *tuple = Tuple{values, &GetOutputSchema ()}; *rid = RID{}; outer_tuple_available_ = child_executor_->Next (&outer_tuple_, &outer_rid); outer_matched_ = false ; inner_rids_.clear (); inner_match_idx_= 0 ; return true ; } outer_tuple_available_ = child_executor_->Next (&outer_tuple_, &outer_rid); if (!outer_tuple_available_) { break ; } outer_matched_ = false ; inner_rids_.clear (); inner_match_idx_= 0 ; auto key_value = plan_->KeyPredicate ()->Evaluate (&outer_tuple_, child_executor_->GetOutputSchema ()); std::vector<Value> key_values{key_value}; Tuple index_key{key_values, &index_info->key_schema_}; index_info->index_->ScanKey (index_key, &inner_rids_, exec_ctx_->GetTransaction ()); } return false ; }
同样,举个例子形象说明。
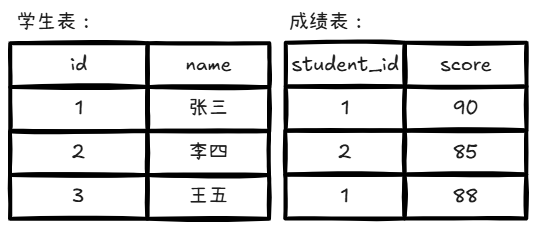
假设有以下两个表:
假设成绩表的student_id字段上有索引。SQL如下:
1 2 3 SELECT students.id, students.name, scores.scoreFROM studentsJOIN scores ON students.id = scores.student_id;
第一步:从学生表(外表)取出第一行,比如 {1, ”张三“};
第二步:用 id = 1 去成绩表(内表)的 student_id 索引里查找所有 student_id = 1 的行,查找两行 {90, 88}
第三步:组合成结果:{1,”张三“,90} {1,“张三”,88}
第四步:换下一行,{2,“李四”}
第五步:同理,直到 students 表遍历完
NLJ 和 NIJ 的区别
NLJ 实现简单,适用于任何连接条件;但性能差,尤其当内表很大时效率极低
利用索引查询内表匹配行的速度很快,效率高于NLJ;但如果外表很大时,每次都有索引键,索引查找的开销也会积累。
Task #3 - HashJoin Executor and Optimization
src/execution/hash_join_executor.cpp
HashJoin 从 Task#2 的实现可知,NLJ 通过双重循环暴力枚举两表所有组合,效率最低;NIJ 则在外表循环的基础上,利用内表的索引加速查找匹配行,适合内表有索引的情况。而 HashJoin 首先将一张表的连接键构建为哈希表,再用另一张表的连接键进行高效查找,适合大表等值连接,通常在无索引或多对多等值连接时性能最优。从效率来排 HashJoin > NIJ > NLJ,但 HashJoin 只能用在等值连接(equi-join)中,因为哈希表只能做键是否相等的查找,范围条件(>或者<)或带计算的条件无法直接用哈希匹配 。
等值比较 是指,连接条件里两边都是“某个表的一列”,并且用等号比较。比如 a.id = b.student_id。它不是“列=常量(a.id = 10)”,也不是”列和计算”(比如 a.id + 1= b.student_id),更不是大小比较 (a.id > b.student_id)。只能是左表的一列等于右表的一列。
简单来说,hashJoin 就是对每个元组根据分组列和聚合列分别构造出一个数组作为哈希表的Key和Value, 然后针对相同的Key对Value做聚合。
在实现 HashJoinExecutor 之前,先解释一下什么是哈希键的自定义比较和哈希函数。哈希键的自定义比较函数和哈希函数主要是为了让复合数据结构能够作为哈希表的键而必须实现的操作。
自定义比较函数 主要用来判断什么时候两个键才能被视为相等,比如对于包含多个列的对象,只有当所有列都相等时,整个键才相等,并且要确保包含 NULL 的键不会与任何键相等;在下述实现中,std::vector<Value> 用于承载一列或多列的连接键,重载的 operator== 逐列使用 Value::CompareEquals 比较相等,只有比较结果为 CmpBool::CmpTrue 时判定为相等;一旦列数不一致或任一列比较结果非真(包括 NULL 导致的 CmpNull),就视为不相等,确保让复合键的相等关系和 SQL 等值连接的语义对齐:包含 NULL 的连接键不会彼此相等,因此不会参与等值匹配。示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 struct HashJoinKey { std::vector<Value> keys_; explicit HashJoinKey (std::vector<Value> key) : keys_(std::move(key)) { auto operator ==(const HashJoinKey& other) const ->bool { if (keys_.size () != other.keys_.size ()) { return false ; } for (size_t i = 0 ; i < keys_.size (); ++i) { if (keys_[i].CompareEquals (other.keys_[i]) != CmpBool::CmpTrue ){ return false ; } } return true ; } };
而自定义哈希函数 主要为了将复合键转换为哈希值,它需要遍历键的每一个分量,对每个分裂计算哈希,然后将这些哈希值组成一个整体的哈希值。下述哈希函数的实现中,对每个 Value 调用 HashUtil::HashValue 得到列哈希,再通过 HashUtil::CombineHashes 顺序合并为整体哈希值。该组合方式既保留列的顺序信息,又能在不同列数、不同取值时产生分布较好的散列,降低碰撞概率。实现如下:
1 2 3 4 5 6 7 8 9 10 template <>struct hash <bustub::HashJoinKey> { auto operator () (const bustub::HashJoinKey& key) const -> size_t size_t hash_val = 0 ; for (const auto & val : key.keys_) { hash_val = bustub::HashUtil::CombineHashes (hash_val, bustub::HashUtil::HashValue (&val)); } return hash_val; } };
HashJoinKey 和 hash<bustub::HashJoinKey> 在构建端能把相等的多列连接键归并到同一哈希桶并聚集对应左侧(外表)元组列表,在探测端按相同规则计算键后能以均摊O(1)的复杂度查到候选匹配,同时遵循SQL等值连接关于NULL的语义规则。
举个例子说明:假设有一个 join 查询:SELECT * FROM A JOIN B ON A.id = B.id AND A.name = B.name, 连接键包含两列:id 和 name
表 A 的数据:{1, “A”}、{2, “B”}、{3, NULL}
表 B 的数据:{1, “A”}、{2, ”B”}、{3, “C”}
在 HashJoin 的构建阶段 , HashJoinKey 会为表 A 的每一行创建复合键:
键1: [id = 1, name = “A”]
键2: [id = 2, name = “B”]
键3: [id = 3, name = NULL]
自定义的比较函数确保:
键1和键1相等(所有列都相等)
键1和键2不相等(name、id列均不同)
键3和任何键都不相等(包含NULL)
自定义哈希函数为每个键计算哈希值,相同的键产生相同的哈希值。
在 HashJoin 的探测阶段 ,对于表 B 的每一行,也创建相同的复合键,然后用这个键在哈希表中查找匹配的左侧元组,只有真正匹配的行才会被连接(比如表A和表B的{1, “A”}行),而包含 NULL 的行不会被错误的匹配。
上面提到了 HashJoin 的构建阶段 和探测阶段 ,什么是构建和探测呢?
HashJoin 的构建阶段发生在 Init() 中,目标是建立哈希索引。我们的实现中是从左子执行器(一般选择较小的表作为构建端)逐行读取元组,对每个元组按左连接键表达式求值得到连接键,构造 HashJoinKey 对象,并将该键插入到 hash_table 中。如果哈希表中已存在相同键,则将新的左侧元组追加到对应键的 std::vector<Tuple> 中;如果是新键,则创建新的 vector 并插入该元组。构建完之后,哈希表就能形成从连接键 到所有具有该键值的左表元组列表 的映射关系。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 void HashJoinExecutor::Init () left_executor_->Init (); right_executor_->Init (); hash_table_.clear (); left_tuples_.clear (); Tuple left_tuple{}; RID left_rid{}; while (left_executor_->Next (&left_tuple, &left_rid)) { std::vector<Value> left_key_values; for (const auto &expr : plan_->LeftJoinKeyExpressions ()) { left_key_values.emplace_back (expr->Evaluate (&left_tuple, left_executor_->GetOutputSchema ())); } HashJoinKey left_key{left_key_values}; hash_table_[left_key].emplace_back (left_tuple); if (plan_->GetJoinType () == JoinType::LEFT) { left_tuples_.emplace_back (left_tuple); } } current_matches_.clear (); current_match_idx_ = 0 ; right_tuple_available_ = false ; left_matched_ = false ; if (plan_->GetJoinType () == JoinType::LEFT) { left_matched_flags_.clear (); left_matched_flags_.resize (left_tuples_.size (), false ); current_left_idx_ = 0 ; } }
探测阶段发生在 Next() 中,目标是利用已构建的哈希表快速找到匹配。我们的实现中是从右子执行器逐行读取元组,对每个元组按右连接键表达式求值得到连接键,构造 HashJoinKey 对象,然后用该键在哈希表中查找。如果找到匹配的键,说明存在连接键值相等的左侧元组,此时将匹配的左侧元组列表缓存到 current_matches_ 中,并逐行产出连接结果;若为左外连接,还需要处理右表元组未匹配的清空,即输出右表元组与左表空值拼接的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 auto HashJoinExecutor::Next (Tuple *tuple, RID *rid) -> bool if (plan_->GetJoinType () == JoinType::LEFT) { while (true ) { if (current_match_idx_ < current_matches_.size ()) { const auto &left_tuple = current_matches_[current_match_idx_++]; return true ; } if (!right_tuple_available_) { right_tuple_available_ = right_executor_->Next (¤t_right_tuple_, ¤t_right_rid_); } if (!right_tuple_available_) { break ; } std::vector<Value> right_key_values; for (const auto &expr : plan_->RightJoinKeyExpressions ()) { right_key_values.emplace_back (expr->Evaluate (¤t_right_tuple_, right_executor_->GetOutputSchema ())); } HashJoinKey right_key{right_key_values}; auto it = hash_table_.find (right_key); if (it != hash_table_.end ()) { current_matches_ = it->second; current_match_idx_ = 0 ; left_matched_ = true ; } else { current_matches_.clear (); current_match_idx_ = 0 ; left_matched_ = false ; } right_tuple_available_ = false ; } while (current_left_idx_ < left_tuples_.size ()) { if (!left_matched_flags_[current_left_idx_]) { } current_left_idx_++; } return false ; } while (true ) { if (current_match_idx_ < current_matches_.size ()) { const auto &left_tuple = current_matches_[current_match_idx_++]; return true ; } if (!right_tuple_available_) { right_tuple_available_ = right_executor_->Next (¤t_right_tuple_, ¤t_right_rid_); } if (!right_tuple_available_) { return false ; } std::vector<Value> right_key_values; for (const auto &expr : plan_->RightJoinKeyExpressions ()) { right_key_values.emplace_back (expr->Evaluate (¤t_right_tuple_, right_executor_->GetOutputSchema ())); } HashJoinKey right_key{right_key_values}; auto it = hash_table_.find (right_key); if (it != hash_table_.end ()) { current_matches_ = it->second; current_match_idx_ = 0 ; left_matched_ = true ; } else { current_matches_.clear (); current_match_idx_ = 0 ; left_matched_ = false ; } right_tuple_available_ = false ; } }
可以看到,HashJoin 中左外连接情况下,右表被当作保留测处理,但是在TASK2中实现的NLJ、NIJ 连接算子中,左表(外表)才是保留侧,这是为什么?在不同的连接算子中,哪个表是“保留侧”?
这是因为在 hashJoin 中,一般用较小的表作为构建端,我们在实现的时候选择了左表作为构建端,然后用右表进行探测,对右表的每一行在左表形成的构建表中寻找匹配,当右表的某行在左表没有匹配时,输出右表的值和左表的NULL,因此右表作为保留测。但当构建端是右表时,保留测变为了左表。这是个动态的过程。
Optimizing NestedLoopJoin to HashJoin
src/optimizer/nlj_as_hash_join.cpp
上面提到了 NLJ 相比 NIJ和hashJoin,NLJ 的效率太差。本小节尝试对 NLJ 优化为 HashJoin(自动将满足固定条件的NLJ转换为HashJoin)。大概思路是递归遍历计划树,识别处等值连接(即连接谓词为等值比较,且左右两侧均为列值表达式),并将其替换为HashJoinPlanNode,简单来说就是:将连接谓词中的“列 = 列”条件抽取成左右连接键列表,左侧构建哈希表、右侧用键探测 。时间复杂度从(m*n)将为O(m+n)。
列= 列的等值比较是指,连接条件里两边都是“某个表的一列”,并且用等号比较。比如 a.id = b.student_id。它不是“列=常量(a.id = 10)”,也不是”列和计算”(比如 a.id + 1= b.student_id),更不是大小比较 (a.id > b.student_id)。只能是左表的一列等于右表的一列。
为什么优化为 HashJoin 可以提升连接效率?
HashJoin 的核心思想是“先构建,再探测”。构建阶段,扫描左表,对每一行计算连接键的哈希值,并将该行插入到哈希表对应的桶。在探测阶段,扫描右表,对每一行计算连接键的哈希值,在哈希表中查找匹配的行,从而实现快速等值连接。
根本原因还是在于,构建阶段只需要扫描一次左表,探测阶段对每个右表行都能在均摊O(1)时间内找到所有匹配的左表行,避免了嵌套循环中重复扫描的问题。而且在左表相对较小时,完全可以将哈希表放在内存,进一步减少IO开销。
触发条件:
必须是 equi-join,且两侧键分别来自左右输入各一列;并允许按 AND 连接的多列键
仅对 Inner Join 触发规则 ,避免外连接语义处理复杂度(外连接涉及保留侧与NULL生成语义,改写很复杂);若谓词含非等值或混合条件,当前实现选择不该写(保持NLJ)
Optimizer::OptimizeNLJAsHashJoin是我们实现的核心,通过自底向上的方式遍历查询计划树,对于每个计划节点,首先递归优化其子节点,确保子节点已经是最优的。然后检查当前节点是否为NLJ,尝试把 NLJ 的谓词拆解出“等值连接键”,成功就使用新的HashJoinPlanNode来替换原有的NLJ,失败就不变:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 auto Optimizer::OptimizeNLJAsHashJoin (const AbstractPlanNodeRef &plan) -> AbstractPlanNodeRef std::vector<AbstractPlanNodeRef> children; for (const auto &child : plan->GetChildren ()) { children.emplace_back (OptimizeNLJAsHashJoin (child)); } auto optimized_plan = plan->CloneWithChildren (std::move (children)); if (optimized_plan->GetType () == PlanType::NestedLoopJoin) { const auto &nlj_plan = dynamic_cast <const NestedLoopJoinPlanNode &>(*optimized_plan); if (nlj_plan.GetJoinType () == JoinType::INNER || nlj_plan.GetJoinType () == JoinType::LEFT) { std::vector<AbstractExpressionRef> left_keys; std::vector<AbstractExpressionRef> right_keys; if (ExtractJoinKeys (nlj_plan.Predicate (), left_keys, right_keys) && !left_keys.empty ()) { return std::make_shared <HashJoinPlanNode>(nlj_plan.output_schema_, nlj_plan.GetLeftPlan (), nlj_plan.GetRightPlan (), std::move (left_keys), std::move (right_keys), nlj_plan.GetJoinType ()); } } } return optimized_plan; }
从谓词中提取等值连接键的工作由 IsEquiComparison、IsColumnExpression 和 ExtractJoinKeys 配合完成。IsEquiComparison 只认“=” 这种等值比较;IsColumnExpression 确保两边都是列;ExtractJoinKeys 负责把复杂谓词拆开(目前只支持AND),并保证一边来自左表,另一边来自右表,这样才能将哈希键的左键/右键一一对应起来。核心逻辑是,如果是AND,就拆两边;如果是“列=列”,就按左右输入的 tuple_idx 把它放进 right_keys 和 left_keys 。实现如下:
列绑定里用 tuple_idx 区分左右子:左子为0,右子为1。提取键时需要把任意(左,右)或(右,左)的等值对,规整为:left_keys 对应左子、right_keys 对应右子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 auto IsEquiComparison (const AbstractExpressionRef &expr) -> bool const auto *comp_expr = dynamic_cast <const ComparisonExpression *>(expr.get ()); return comp_expr != nullptr && comp_expr->comp_type_ == ComparisonType::Equal; } auto IsColumnExpression (const AbstractExpressionRef& expr) -> bool return dynamic_cast <const ColumnValueExpression *>(expr.get ()) != nullptr ; } auto ExtractJoinKeys (const AbstractExpressionRef& predicate, std::vector<AbstractExpressionRef>& left_keys,std::vector<AbstractExpressionRef>& right_keys) -> bool if (predicate == nullptr ) { return false ; } if (const LogicExpression* logic_expr = dynamic_cast <const LogicExpression*>(predicate.get ()); logic_expr != nullptr ) { if (logic_expr->logic_type_ == LogicType::And) { return ExtractJoinKeys (logic_expr->GetChildAt (0 ), left_keys, right_keys) && ExtractJoinKeys (logic_expr->GetChildAt (1 ), left_keys, right_keys); } return false ; } if (IsEquiComparison (predicate)) { const auto & comp_expr = dynamic_cast <const ComparisonExpression&>(*predicate); auto left_expr = comp_expr.GetChildAt (0 ); auto right_expr = comp_expr.GetChildAt (1 ); if (IsColumnExpression (left_expr) && IsColumnExpression (right_expr)) { const auto & left_col = dynamic_cast <const ColumnValueExpression&>(*left_expr); const auto & right_col = dynamic_cast <const ColumnValueExpression&>(*right_expr); if (left_col.GetTupleIdx () == 0 && right_col.GetTupleIdx () ==1 ) { left_keys.emplace_back (left_expr); right_keys.emplace_back (right_expr); return true ; } else if (left_col.GetTupleIdx () == 1 && right_col.GetTupleIdx () ==0 ) { left_keys.emplace_back (right_expr); right_keys.emplace_back (left_expr); return true ; } } } return false ; }
把这些拼起来看,整体路径就是:遍历计划树,遇到NLJ且是INNER,就去它的谓词里找“列=列”的等值条件,还要确保确实是跨左右输入各取一列;如果找到了,就把这些列表达式成对放进 left_keys/right_keys,并用它们新建一个 HashJoinPLanNode。执行层拿到这个哈希计划节点后,在Init() 先用左输入构建哈希表,再用右输入逐行探测。
为什么只处理INNER JOIN,而不是LEFT/RIGHT OUTER?
因为外连接有“保留测必须产出”的规则,哈希连接需要额外跟踪哪些行没匹配到并补NULL,过程很复杂,目前我只实现了内连接转换。
如果还没有理解,可以看下面这个例子,将原理和实践联系起来:
假如有两个表:
表A:id,name,class_id
表B:student_id,class_id,score
执行以下SQL:
1 2 SELECT * FROM A JOIN B ON A.id = B.student_id AND A.age = B.age;
(1) 优化器首先生成一个 NLJ 查询计划 :
1 2 3 4 5 6 NestedLoopJoin { type: INNER, predicate: (A.id = B.student_id AND A.class_id = B.class_id), left: Scan(A), right: Scan(B) }
(2) 优化器识别 NLJ 节点 :当优化器 OptimizeNLJAsHashJoin 遍历到这个节点时,发现:这个一个 NestedLoopJoin 节点,连接类型是Inner并且满足优化条件。
(3) 提取等值连接键 :优化器调用 ExtractJoinKeys 函数分析谓词 (A.id = B.student_id AND A.class_id= B.class_id):
处理第一个条件 A.id = B.student_id:
左边 A.id 来自左表 A,tuple_idx = 0
右表 B.student_id 来自右表 B,tuple_idx = 1
并且是一个有效的等值连接键
输出 left_keys = [A.id], right_keys = [B.student_id]
处理第二各条件 A.class_id= B.class_id:
左边 A.age来自左表 A,tuple_idx = 0
右表 B.age来自右表 B,tuple_idx = 1
并且是一个有效的等值连接键
输出 left_keys = [A.id, A.class_id], right_keys = [B.student_id, B.class_id]
(4) 创建 HashJoin 计划
由于成功提取出了等值连接键,优化器创建新的 HashJoinPlanNode:
1 2 3 4 5 6 7 HashJoinPlanNode { type: INNER, left_keys = [A.id, A.class_id], right_keys = [B.student_id, B.class_id] left: Scan(A), right: Scan(B) }
(5)执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 // 原本的 NLJ 执行方式 for each a in A: for each b in B: if a.id == b.student_id AND a.class_id == b.class_id: output(a, b) // 新的 HashJoin 执行方式 // 构建阶段:扫描表 A for each a in A: key = hash(a,id, a.class_id) hash_table[key].emplace_back(a) // 探测阶段:扫描表 B for each b in B: key = hash(b.student_id, b.class_id) matches = hash_table[key] for each a in matches: if a.id == b.student_id AND a.class_id == b.class_id: output(a, b)
复杂度从O(m*n)降到O(m+n)。
Q&A
1.HashJoin LEFT JOIN逻辑有问题
HashJoin 在构建阶段一般都是以小表为基准构建哈希表,但是官网task3要求实现的 hashJoin 以左表为基准构建哈希表,使用右表进行探测。我这里实现反了,更正。
2.LEFT JOIN元组跟踪缺失
之前的实现没有保存左表元组,无法处理LEFT JOIN,在头文件新建变量 left_tuple_tuple_ 和 left_matched_flags_ 用于跟踪左表元组,记录哪些左表元素被跟踪了。
test 1 2 3 4 5 6 7 8 9 10 make -j$(nproc) sqllogictest ./bin/bustub-sqllogictest ../test/sql/p3.07-simple-agg.slt --verbose ./bin/bustub-sqllogictest ../test/sql/p3.08-group-agg-1.slt --verbose ./bin/bustub-sqllogictest ../test/sql/p3.09-group-agg-2.slt --verbose ./bin/bustub-sqllogictest ../test/sql/p3.10-simple-join.slt --verbose ./bin/bustub-sqllogictest ../test/sql/p3.11-multi-way-join.slt --verbose ./bin/bustub-sqllogictest ../test/sql/p3.12-repeat-execute.slt --verbose ./bin/bustub-sqllogictest ../test/sql/p3.13-nested-index-join.slt --verbose ./bin/bustub-sqllogictest ../test/sql/p3.14-hash-join.slt --verbose ./bin/bustub-sqllogictest ../test/sql/p3.15-multi-way-hash-join.slt --verbose
p3.07-simple-agg.slt 测试成功
p3.08-group-agg-1.slt 测试成功
p3.09-group-agg-2.slt 测试成功
p3.10-simple-join.slt 测试成功:
p3.11-multi-way-join.slt 测试成功:
p3.12-repeat-execute.slt 测试成功:
p3.13-nested-index-join.slt 测试成功:
p3.14-hash-join.slt 测试成功
p3.15-multi-way-hash-join.slt 测试成功: