Task #4: External Merge Sort + Limit Executors Task 4 需要实现 external merge sort executor 和 limit executor,主要负责处理 ORDER、BY和LIMIT子句。
External Merge Sort external merge sort executor 主要用于对大量数据进行外部归并排序,因为内存相比磁盘小很多很多,大数据一般不会完全写入到内存中,传统的内存排序算法(快排、归并)在这种情况下无法工作。
external merge sort executor 的核心思想是,将大数据集分割为多个小块,然后将每个小块写入到内存中进行排序,并将排序后的数据小块逐步归并,最后得到排序结果。因为主要过程需要多次读写磁盘分批量写入内存,所以内存的压力相对较小。
在实现算法之前,需要额外创建两个类 SortPage 和 MergeSortRun。SortPage 负责存放外部归并排序过程中产生的中间数据(2024 fall 无需处理变长字段如 VARCHAR,只支持定长元组),MergeSortRun 负责管理一组已排序的页面并定义相关迭代器用于访问数据,ExternalMergeSortExecutor 负责协调整个排序过程。
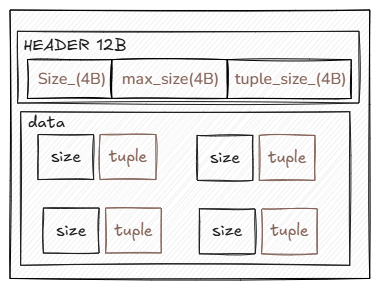
SortPage 和数据库页面不一样,它主要用于存储排序数据,结构如下所示:
一个完整的 SortPage 包含头部 HEADER 和数据主体 data,头部用于存放元数据,比如 SortPage 中元组的数量、最大容纳数量以及每个元组大小(2024 fall 是定长),一共12B;数据主体分为 size 和 tuple 两部分,前者存储元组数据部分的长度(4B,虽然是定长数据,但可能用于校验或兼容设计),后者直接存储元组(大小由 schema.GetInlinedStorageSize() 确定)。
MergeSortRun 表示 external merge sort 中的一个 运行 (Run)—— 即一段已排序的数据集(包含多个SortPage,数据在块内和块间都是有序的,其实就是代表一组已排序的元组,只不过这些被排序后的元组可能分布在多个SortPage中,MergeSortRun负责统筹这一组元组的所有sortPage页 )。比如,当数据太大无法一次性排序时,会先把数据分成 3 块,每块在内存中排好序后写入磁盘,这 3 块就是 3 个 “运行”(我的实现中,一个 MergeSortRun 包含 4 个 sortPage );后续会逐步合并这些运行,直到得到一个完整的排序结果。
内部定义了一个迭代器,用于遍历MergeSortRun中的所有元组(跨多个SortPage),方便后续合并时比较各运行的元组。实现了以下三个迭代器方法:
operator++():移动到下一个元组。如果当前SortPage的元组已读完(tuple_idx_等于页中元组数量),则切换到下一个SortPage(pages_idx_加 1),并通过bpm_加载新页;operator*():获取当前指向的元组。通过page_guard_获取当前SortPage,调用GetTupleAt(tuple_idx_)读取元组;operator==/`operator!=判断是否遍历结束
ExternalMergeSortExecutor 负责协调整个流程,共有三个阶段:创建初始排序运行->归并排序->迭代
首先,从子执行器读取多个元组的排序键和元组本身,并存储至 SortEntry,然后使用 std::sort 将这些条目排序,最后将排序后的元组写入排序页面,简单来说就是将原始数据分成若干小块,每块在内存中排序后存入磁盘 。这里之所以可以调用 std::sort 排序是因为,虽然我们没办法对所有数据一次性内存排序,但可以对单个页面内的数据进行内存排序。
流程如下:
从子执行器(child_executor_)读取元组,存入临时列表 entries(每个元素包含 “排序键” 和元组本身,方便排序)
当读取的元组数量达到 max_size * initial_page_cnt(即 4 个页能容纳的总元组)时,停止读取
对 entries 用 std::sort 排序(内存中排序)
将排序后的元组写入 SortPage:
一个页存满后(达到 max_size),创建新页继续写;
所有元组写完后,这些页组成一个 “运行”(一个MergeSortRun包含4个sortPage),加入 runs_
重复上述步骤,直至子执行器无更多弹出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 void ExternalMergeSortExecutor<K>::CreateInitialRuns () { const int initial_page_cnt = 4 ; Tuple child_tuple{}; RID rid; const int tuple_size = static_cast <int >(sizeof (int32_t ) + child_executor_->GetOutputSchema ().GetInlinedStorageSize ()); const int max_size = (BUSTUB_PAGE_SIZE - SORT_PAGE_HEADER_SIZE) / tuple_size; while (true ) { std::vector<page_id_t > pages; page_id_t page_id = exec_ctx_->GetBufferPoolManager ()->NewPage (); pages.emplace_back (page_id); int cnt = 0 ; WritePageGuard page_guard = exec_ctx_->GetBufferPoolManager ()->WritePage (page_id); auto sort_page = page_guard.AsMut <SortPage>(); sort_page->Init (0 , max_size, tuple_size); std::vector<SortEntry> entries; bool tuples_over = false ; while (cnt < max_size * initial_page_cnt) { if (child_executor_->Next (&child_tuple, &rid)) { entries.push_back ({GenerateSortKey (child_tuple, plan_->GetOrderBy (), GetOutputSchema ()), std::move (child_tuple)}); cnt++; } else { tuples_over = true ; break ; } } if (cnt == 0 && tuples_over) { exec_ctx_->GetBufferPoolManager ()->DeletePage (page_id); break ; } std::sort (entries.begin (), entries.end (), cmp_); cnt = 0 ; for (const auto &entry : entries) { if (cnt == max_size) { page_id = exec_ctx_->GetBufferPoolManager ()->NewPage (); pages.emplace_back (page_id); page_guard = exec_ctx_->GetBufferPoolManager ()->WritePage (page_id); sort_page = page_guard.AsMut <SortPage>(); sort_page->Init (0 , max_size, tuple_size); cnt = 0 ; } sort_page->InsertTuple (entry.second); cnt++; } runs_.emplace_back (MergeSortRun (pages, exec_ctx_->GetBufferPoolManager ())); if (tuples_over) break ; } }
第二阶段是归并排序(二路归并),通过第一阶段初始化好的“运行”中的迭代器,比较两个“运行”中的元组,然后将大(或者小)的写入新的 归并页面,直到只剩一个块。第三阶段在第二阶段之后完成,负责清理旧页面,避免“僵尸页”。主要流程为:
遍历 runs_,每次取 2 个运行进行合并
初始化合并后的新页列表(new_pages),并准备一个新的 SortPage 用于写入合并结果
二路归并核心逻辑:
用两个迭代器分别遍历两个运行中的元组
比较两个迭代器指向的元组,将较小的元组写入新页
当一个页存满(max_size),创建新页继续写
处理剩余元组,当其中一个运行的元组遍历完后,将另一个运行中剩余的元组全部写入新页
清理旧页,合并完成后,删除原来两个运行占用的页
新生成的运行加入 new_runs 列表,替换原来的 runs_
重复上述过程,直到 runs_ 中只剩 1 个运行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 void ExternalMergeSortExecutor<K>::MergeRuns () { while (runs_.size () > 1 ) { std::vector<MergeSortRun> new_runs; const int n = runs_.size (); for (int i = 0 ; i < n; i += 2 ) { if (i + 1 >= n) { new_runs.push_back (runs_[i]); break ; } std::vector<page_id_t > new_pages; auto iter_a = runs_[i].Begin (); auto iter_b = runs_[i + 1 ].Begin (); const int tuple_size = static_cast <int >(sizeof (int32_t ) + GetOutputSchema ().GetInlinedStorageSize ()); const int max_size = (BUSTUB_PAGE_SIZE - SORT_PAGE_HEADER_SIZE) / tuple_size; page_id_t new_page_id = exec_ctx_->GetBufferPoolManager ()->NewPage (); new_pages.emplace_back (new_page_id); auto page_guard = exec_ctx_->GetBufferPoolManager ()->WritePage (new_page_id); auto sort_page = page_guard.AsMut <SortPage>(); sort_page->Init (0 , max_size, tuple_size); int cnt = 0 ; while (iter_a != runs_[i].End () && iter_b != runs_[i + 1 ].End ()) { if (cnt >= max_size) { new_page_id = exec_ctx_->GetBufferPoolManager ()->NewPage (); new_pages.emplace_back (new_page_id); page_guard = exec_ctx_->GetBufferPoolManager ()->WritePage (new_page_id); sort_page = page_guard.AsMut <SortPage>(); sort_page->Init (0 , max_size, tuple_size); cnt = 0 ; } SortEntry entry_a = {GenerateSortKey ((*iter_a), plan_->GetOrderBy (), GetOutputSchema ()), *iter_a}; SortEntry entry_b = {GenerateSortKey ((*iter_b), plan_->GetOrderBy (), GetOutputSchema ()), *iter_b}; if (cmp_ (entry_a, entry_b)) { sort_page->InsertTuple (entry_a.second); ++iter_a; } else { sort_page->InsertTuple (entry_b.second); ++iter_b; } cnt++; } while (iter_a != runs_[i].End ()) { if (cnt >= max_size) { new_page_id = exec_ctx_->GetBufferPoolManager ()->NewPage (); new_pages.emplace_back (new_page_id); page_guard = exec_ctx_->GetBufferPoolManager ()->WritePage (new_page_id); sort_page = page_guard.AsMut <SortPage>(); sort_page->Init (0 , max_size, tuple_size); cnt = 0 ; } sort_page->InsertTuple (*iter_a); ++iter_a; cnt++; } while (iter_b != runs_[i + 1 ].End ()) { if (cnt >= max_size) { new_page_id = exec_ctx_->GetBufferPoolManager ()->NewPage (); new_pages.emplace_back (new_page_id); page_guard = exec_ctx_->GetBufferPoolManager ()->WritePage (new_page_id); sort_page = page_guard.AsMut <SortPage>(); sort_page->Init (0 , max_size, tuple_size); cnt = 0 ; } sort_page->InsertTuple (*iter_b); ++iter_b; cnt++; } for (auto page_id : runs_[i].GetPages ()) { exec_ctx_->GetBufferPoolManager ()->DeletePage (page_id); } for (auto page_id : runs_[i + 1 ].GetPages ()) { exec_ctx_->GetBufferPoolManager ()->DeletePage (page_id); } new_runs.emplace_back (MergeSortRun (new_pages, exec_ctx_->GetBufferPoolManager ())); } runs_ = std::move (new_runs); } }
Limit Executors LimitExecutor相对比较简单,主要作用是限制从子执行器输出的元组数量,核心是通过维护计数器 cnt_ 记录已经输出的元组数量。
在 LimitExecutor 的 Init 中,初始化子执行器,并将计数器置零;在 Next 中,首先检查是否已经达到限制数量,如果达到则返回 false,否则,则尝试从子执行器中获取下一个元组,获取成功后,计数器加一并返回true。
test 1 2 3 4 make -j$(nproc) sqllogictest ./bin/bustub-sqllogictest ../test/sql/p3.16-sort-limit.slt --verbose ./bin/bustub-sqllogictest ../test/sql/p3.18-integration-1.slt --verbose ./bin/bustub-sqllogictest ../test/sql/p3.19-integration-2.slt --verbose
submit 先在build文件夹下依次执行以下命令:
1 2 make format make check-clang-tidy-p3
然后执行:
会在根目录下生成名为 project3-submission.zip的压缩包,将其上传至 Gradescope 即可
我提交检测的时候,说除了所需的代码文件外,还需要 GRADESCOPE.md 签名文件,大概查了下,这是23年开始新加的要求,除了PROJECT#0不需要外,其他项目都需要。运行下面指令生成:
1 2 cd .. python3 gradescope_sign.py
然后填一下自己的名字、院校和Github ID即可,GRADESCOPE.md 会自行添加至刚才生成的project2-submission.zip压缩包中。
提交编译时报错,但是提交文件并没有 executor_factory.cpp 并且没有该错误,很明显gradescope 的代码库和 https://github.com/cmu-db/bustub/releases/tag/v20241207-2024fall 2024 fall 最新的版本不一样,不过官网已经提供了所有测试,本地测试全都通过。